Hibernate Search consists of an indexing and an index search component. Both are backed by Apache Lucene.
Each time an entity is inserted, updated or removed in/from the database, Hibernate Search keeps track of this event (through the Hibernate event system) and schedules an index update. All the index updates are handled without you having to use the Apache Lucene APIs (see Section 3.1, “Enabling Hibernate Search and automatic indexing”).
To interact with Apache Lucene indexes, Hibernate Search has the
notion of DirectoryProviders. A directory provider
will manage a given Lucene Directory type. You can
configure directory providers to adjust the directory target (see Section 3.2, “Directory configuration”).
Hibernate Search uses the Lucene index to search an entity and
return a list of managed entities saving you the tedious object to Lucene
document mapping. The same persistence context is shared between Hibernate
and Hibernate Search. As a matter of fact, the
FullTextSession is built on top of the Hibernate
Session so that the application code can use the unified
org.hibernate.Query or
javax.persistence.Query APIs exactly the same way a
HQL, JPA-QL or native query would do.
To be more efficient Hibernate Search batches the write interactions with the Lucene index. There are currently two types of batching. Outside a transaction, the index update operation is executed right after the actual database operation. This is really a no batching setup. In the case of an ongoing transaction, the index update operation is scheduled for the transaction commit phase and discarded in case of transaction rollback. The batching scope is the transaction. There are two immediate benefits:
Performance: Lucene indexing works better when operation are executed in batch.
ACIDity: The work executed has the same scoping as the one executed by the database transaction and is executed if and only if the transaction is committed. This is not ACID in the strict sense of it, but ACID behavior is rarely useful for full text search indexes since they can be rebuilt from the source at any time.
You can think of those two batch modes (no scope vs transactional) as the equivalent of the (infamous) autocommit vs transactional behavior. From a performance perspective, the in transaction mode is recommended. The scoping choice is made transparently. Hibernate Search detects the presence of a transaction and adjust the scoping.
Tip
It is recommended - for both your database and Hibernate Search - to execute your operations in a transaction, be it JDBC or JTA.
Note
Hibernate Search works perfectly fine in the Hibernate / EntityManager long conversation pattern aka. atomic conversation.Note
Depending on user demand, additional scoping will be considered, the pluggability mechanism being already in place.Hibernate Search offers the ability to let the batched work being processed by different back ends. Three back ends are provided out of the box and you have the option to plugin in your own implementation.
In this mode, all index update operations applied on a given node (JVM) will be executed to the Lucene directories (through the directory providers) by the same node. This mode is typically used in non clustered environment or in clustered environments where the directory store is shared.
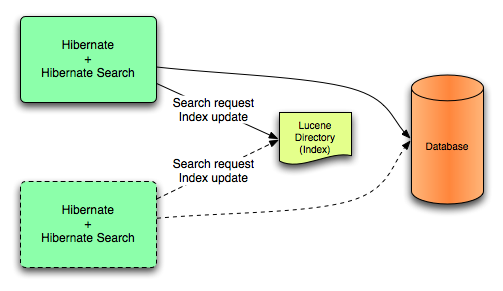
Lucene back end configuration.
This mode targets non clustered applications, or clustered applications where the Directory is taking care of the locking strategy.
The main advantage is simplicity and immediate visibility of the changes in Lucene queries (a requirement in some applications).
All index update operations applied on a given node are sent to a JMS queue. A unique reader will then process the queue and update the master index. The master index is then replicated on a regular basis to the slave copies. This is known as the master/slaves pattern. The master is the sole responsible for updating the Lucene index. The slaves can accept read as well as write operations. However, they only process the read operation on their local index copy and delegate the update operations to the master.
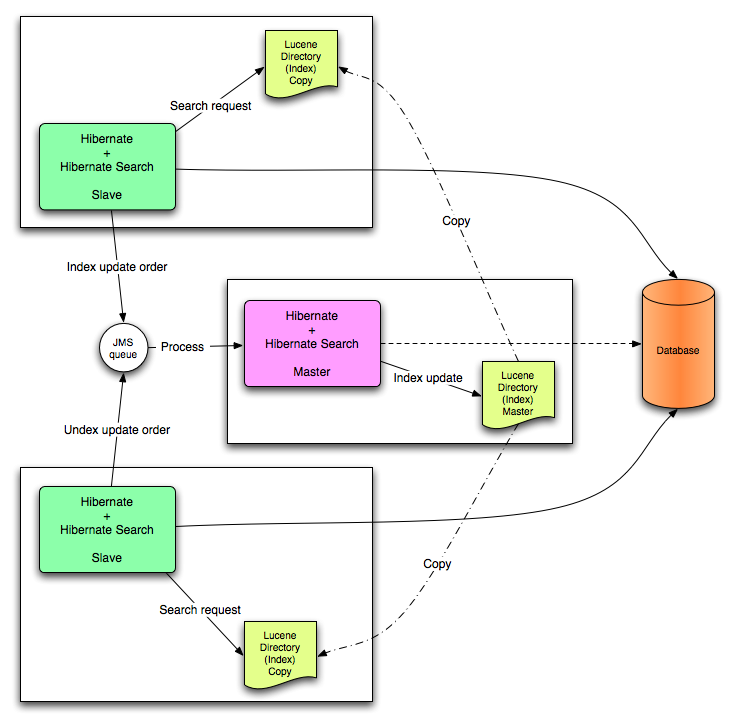
JMS back end configuration.
This mode targets clustered environments where throughput is critical, and index update delays are affordable. Reliability is ensured by the JMS provider and by having the slaves working on a local copy of the index.
The JGroups based back end works similar to the JMS one and is designed after the same master/slave pattern. However, instead of JMS the JGroups toolkit is used as a replication mechanism. This back end can be used as an alternative to JMS when response time is critical, but i.e. JNDI service is not available.
Note
Hibernate Search is an extensible architecture. Feel free to drop ideas for other third party back ends to
hibernate-dev@lists.jboss.org.The indexing work (done by the back end) can be executed synchronously with the transaction commit (or update operation if out of transaction), or asynchronously.
This is the safe mode where the back end work is executed in concert with the transaction commit. Under highly concurrent environment, this can lead to throughput limitations (due to the Apache Lucene lock mechanism) and it can increase the system response time if the backend is significantly slower than the transactional process and if a lot of IO operations are involved.
This mode delegates the work done by the back end to a different thread. That way, throughput and response time are (to a certain extend) decorrelated from the back end performance. The drawback is that a small delay appears between the transaction commit and the index update and a small overhead is introduced to deal with thread management.
It is recommended to use synchronous execution first and evaluate asynchronous execution if performance problems occur and after having set up a proper benchmark.
When executing a query, Hibernate Search interacts with the Apache Lucene indexes through a reader strategy. Choosing a reader strategy will depend on the profile of the application (frequent updates, read mostly, asynchronous index update etc). See also Section 3.9, “Reader strategy configuration”
With this strategy, Hibernate Search will share the same
IndexReader, for a given Lucene index, across
multiple queries and threads provided that the
IndexReader is still up-to-date. If the
IndexReader is not up-to-date, a new one is
opened and provided. Each IndexReader is made of
several SegmentReaders. This strategy only
reopens segments that have been modified or created after last opening
and shares the already loaded segments from the previous instance. This
strategy is the default.
The name of this strategy is shared.
Every time a query is executed, a Lucene
IndexReader is opened. This strategy is not the
most efficient since opening and warming up an
IndexReader can be a relatively expensive
operation.
The name of this strategy is not-shared.