- 3.1. Enabling Hibernate Search and automatic indexing
- 3.2. Directory configuration
- 3.3. Sharding indexes
- 3.4. Sharing indexes
- 3.5. Worker configuration
- 3.6. JMS Master/Slave configuration
- 3.7. JGroups Master/Slave configuration
- 3.8. Infinispan Directory configuration
- 3.9. Reader strategy configuration
- 3.10. Tuning Lucene indexing performance
- 3.11. LockFactory configuration
- 3.12. Exception Handling Configuration
Let's start with the most basic configuration question - how to enable Hibernate Search in your system.
The good news is that Hibernate Search is enabled out of the box
when detected on the classpath by Hibernate Core. If, for some reason
you need to disable it, set
hibernate.search.autoregister_listeners to false.
Note that there is no performance penalty when the listeners are enabled
but no entities are annotated as indexed.
By default, every time an object is inserted, updated or deleted through Hibernate, Hibernate Search updates the according Lucene index. It is sometimes desirable to disable that features if either your index is read-only or if index updates are done in a batch way (see Section 6.3, “Rebuilding the whole index”).
To disable event based indexing, set
hibernate.search.indexing_strategy = manual
Note
In most case, the JMS backend provides the best of both world, a lightweight event based system keeps track of all changes in the system, and the heavyweight indexing process is done by a separate process or machine.
Apache Lucene has a notion of a Directory to
store the index files. The Directory implementation
can be customized and Lucene comes bundled with a file system and an
in-memory implementation. DirectoryProvider is the
Hibernate Search abstraction around a Lucene
Directory and handles the configuration and the
initialization of the underlying Lucene resources. Table 3.1, “List of built-in
DirectoryProviders” shows the list of the directory
providers available in Hibernate Search together with their corresponding
options.
To configure your DirectoryProvider you have
to understand that each indexed entity is associated to a Lucene index
(except of the case where multiple entities share the same index - Section 3.4, “Sharing indexes”). The name of the index is given by
the index property of the
@Indexed annotation. If the
index property is not specified the fully qualified
name of the indexed class will be used as name.
Knowing the index name, you can configure the directory provider and
any additional options by using the prefix
hibernate.search.<indexname>.
The name default
(hibernate.search.default) is reserved and can be
used to define properties which apply to all indexes. Example 3.2, “Configuring directory providers” shows how
hibernate.search.default.directory_provider is used
to set the default directory provider to be the filesystem one.
hibernate.search.default.indexBase sets then the
default base directory for the indexes. As a result the index for the
entity Status is created in
/usr/lucene/indexes/org.hibernate.example.Status.
The index for the Rule entity, however, is
using an in-memory directory, because the default directory provider for
this entity is overriden by the property
hibernate.search.Rules.directory_provider.
Finally the Action entity uses a custom
directory provider CustomDirectoryProvider
specified via
hibernate.search.Actions.directory_provider.
Example 3.1. Specifying the index name
package org.hibernate.example;
@Indexed
public class Status { ... }
@Indexed(index="Rules")
public class Rule { ... }
@Indexed(index="Actions")
public class Action { ... }Example 3.2. Configuring directory providers
hibernate.search.default.directory_provider filesystem hibernate.search.default.indexBase=/usr/lucene/indexes hibernate.search.Rules.directory_provider ram hibernate.search.Actions.directory_provider com.acme.hibernate.provider.CustomDirectoryProvider
Tip
Using the described configuration scheme you can easily define common rules like the directory provider and base directory, and override those defaults later on on a per index basis.
Table 3.1. List of built-in
DirectoryProviders
| Class or shortcut name | Description | Properties |
|---|---|---|
| ram | Memory based directory, the directory will be uniquely
identified (in the same deployment unit) by the
@Indexed.index element | none |
| filesystem | File system based directory. The directory used will be <indexBase>/< indexName > |
|
| filesystem-master | File system based directory. Like
The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes). Note that the copy is based on an incremental copy mechanism reducing the average copy time. DirectoryProvider typically used on the master node in a JMS back end cluster. The |
|
| filesystem-slave | File system based directory. Like
The recommended value for the refresh period is (at least) 50% higher that the time to copy the information (default 3600 seconds - 60 minutes). Note that the copy is based on an incremental copy mechanism reducing the average copy time. DirectoryProvider typically used on slave nodes using a JMS back end. The |
|
| infinispan | Infinispan based directory. Use it to store the index in a distributed grid, making index changes visible to all elements of the cluster very quickly. Also see Section 3.8, “Infinispan Directory configuration” for additional requirements and configuration settings. Infinispan needs a global configuration and additional dependencies; the settings defined here apply to each different index. |
|
Tip
If the built-in directory providers do not fit your needs, you can
write your own directory provider by implementing the
org.hibernate.store.DirectoryProvider interface.
In this case, pass the fully qualified class name of your provider into
the directory_provider property. You can pass any
additional properties using the prefix
hibernate.search.<indexname>.
In some cases it can be useful to split (shard) the indexed data of a given entity into several Lucene indexes.
Warning
This solution is not recommended unless there is a pressing need. Searches will be slower as all shards have to be opened for a single search. Don't do it until you have a real use case!
Possible use cases for sharding are:
A single index is so huge that index update times are slowing the application down.
A typical search will only hit a sub-set of the index, such as when data is naturally segmented by customer, region or application.
By default sharding is not enabled unless the number of shards is
configured. To do this use the
hibernate.search.<indexName>.sharding_strategy.nbr_of_shards
property as seen in Example 3.3, “Enabling index sharding”. In this
example 5 shards are enabled.
Responsible for splitting the data into sub-indexes is the
IndexShardingStrategy. The default sharding
strategy splits the data according to the hash value of the id string
representation (generated by the FieldBridge). This
ensures a fairly balanced sharding. You can replace the default strategy
by implementing a custom IndexShardingStrategy. To
use your custom strategy you have to set the
hibernate.search.<indexName>.sharding_strategy
property.
Example 3.4. Specifying a custom sharding strategy
hibernate.search.<indexName>.sharding_strategy my.shardingstrategy.Implementation
The IndexShardingStrategy also allows for
optimizing searches by selecting which shard to run the query against. By
activating a filter (see Section 5.3.1, “Using filters in a sharded environment”), a
sharding strategy can select a subset of the shards used to answer a query
(IndexShardingStrategy.getDirectoryProvidersForQuery)
and thus speed up the query execution.
Each shard has an independent directory provider configuration. The
DirectoryProvider index names for the Animal entity
in Example 3.5, “Sharding configuration for entity
Animal” are
Animal.0 to Animal.4. In other
words, each shard has the name of it's owning index followed by
. (dot) and its index number (see also Section 3.2, “Directory configuration”).
Example 3.5. Sharding configuration for entity
Animal
hibernate.search.default.indexBase /usr/lucene/indexes hibernate.search.Animal.sharding_strategy.nbr_of_shards 5 hibernate.search.Animal.directory_provider filesystem hibernate.search.Animal.0.indexName Animal00 hibernate.search.Animal.3.indexBase /usr/lucene/sharded hibernate.search.Animal.3.indexName Animal03
In Example 3.5, “Sharding configuration for entity
Animal”, the
configuration uses the default id string hashing strategy and shards the
Animal index into 5 sub-indexes. All sub-indexes
are filesystem instances and the directory where each sub-index is stored
is as followed:
for sub-index 0:
/usr/lucene/indexes/Animal00(shared indexBase but overridden indexName)for sub-index 1:
/usr/lucene/indexes/Animal.1(shared indexBase, default indexName)for sub-index 2:
/usr/lucene/indexes/Animal.2(shared indexBase, default indexName)for sub-index 3:
/usr/lucene/shared/Animal03(overridden indexBase, overridden indexName)for sub-index 4:
/usr/lucene/indexes/Animal.4(shared indexBase, default indexName)
It is technically possible to store the information of more than one entity into a single Lucene index. There are two ways to accomplish this:
Configuring the underlying directory providers to point to the same physical index directory. In practice, you set the property
hibernate.search.[fully qualified entity name].indexNameto the same value. As an example let’s use the same index (directory) for theFurnitureandAnimalentity. We just setindexNamefor both entities to for example “Animal”. Both entities will then be stored in the Animal directory.hibernate.search.org.hibernate.search.test.shards.Furniture.indexName = Animal hibernate.search.org.hibernate.search.test.shards.Animal.indexName = Animal
Setting the
@Indexedannotation’sindexattribute of the entities you want to merge to the same value. If we again wanted allFurnitureinstances to be indexed in theAnimalindex along with all instances ofAnimalwe would specify@Indexed(index="Animal")on bothAnimalandFurnitureclasses.Note
This is only presented here so that you know the option is available. There is really not much benefit in sharing indexes.
It is possible to refine how Hibernate Search interacts with Lucene through the worker configuration. There exist several architectural components and possible extension points. Let's have a closer look.
First there is a Worker. An implementation of
the Worker interface is reponsible for receiving
all entity changes, queuing them by context and applying them once a
context ends. The most intuative context, especially in connection with
ORM, is the transaction. For this reason Hibernate Search will per default
use the TransactionalWorker to scope all changes
per transaction. One can, however, imagine a scenario where the context
depends for example on the number of entity changes or some other
application (lifecycle) events. For this reason the
Worker implementation is configurable as shown in
Table 3.2, “Scope configuration”.
Table 3.2. Scope configuration
| Property | Description |
hibernate.search.worker.scope | The fully qualifed class name of the
Worker implementation to use. If this
property is not set, empty or transaction the
default TransactionalWorker is
used. |
hibernate.search.worker.* | All configuration properties prefixed with
hibernate.search.worker are passed to the
Worker during initialization. This allows adding custom, worker
specific parameters. |
hibernate.search.worker.batch_size | Defines the maximum number of indexing operation batched
per context. Once the limit is reached indexing will be triggered
even though the context has not ended yet. This property only
works if the Worker implementation
delegates the queued work to BatchedQueueingProcessor (which is
what the TransactionalWorker does) |
Once a context ends it is time to prepare and apply the index changes. This can be done synchronously or asynchronously from within a new thread. Synchronous updates have the advantage that the index is at all times in sync with the databases. Asynchronous updates, on the other hand, can help to minimize the user response time. The drawback is potential discrepancies between database and index states. Lets look at the configuration options shown in Table 3.3, “Execution configuration”.
Table 3.3. Execution configuration
| Property | Description |
hibernate.search.worker.execution |
|
hibernate.search.worker.thread_pool.size | Defines the number of threads in the pool for asynchronous execution. Defaults to 1. |
hibernate.search.worker.buffer_queue.max | Defines the maximal number of work queue if the thread poll is starved. Useful only for asynchronous execution. Default to infinite. If the limit is reached, the work is done by the main thread. |
So far all work is done within the same Virtual Machine (VM), no matter which execution mode. The total amount of work has not changed for the single VM. Luckily there is a better approach, namely delegation. It is possible to send the indexing work to a different server by configuring hibernate.search.worker.backend - see Table 3.4, “Backend configuration”.
Table 3.4. Backend configuration
| Property | Description |
hibernate.search.worker.backend |
You can also specify the fully qualified name of
a class implementing
|
Table 3.5. JMS backend configuration
| Property | Description |
hibernate.search.worker.jndi.* | Defines the JNDI properties to initiate the InitialContext (if needed). JNDI is only used by the JMS back end. |
hibernate.search.worker.jms.connection_factory | Mandatory for the JMS back end. Defines the JNDI name to
lookup the JMS connection factory from
(/ConnectionFactory by default in JBoss
AS) |
hibernate.search.worker.jms.queue | Mandatory for the JMS back end. Defines the JNDI name to lookup the JMS queue from. The queue will be used to post work messages. |
Table 3.6. JGroups backend configuration
| Property | Description |
hibernate.search.worker.jgroups.clusterName | Optional for JGroups back end. Defines the name of JGroups channel. |
hibernate.search.worker.jgroups.configurationFile | Optional JGroups network stack configuration. Defines the name of a JGroups configuration file, which must exist on classpath. |
hibernate.search.worker.jgroups.configurationXml | Optional JGroups network stack configuration. Defines a String representing JGroups configuration as XML. |
hibernate.search.worker.jgroups.configurationString | Optional JGroups network stack configuration. Provides JGroups configuration in plain text. |
Warning
As you probably noticed, some of the shown properties are
correlated which means that not all combinations of property values make
sense. In fact you can end up with a non-functional configuration. This
is especially true for the case that you provide your own
implementations of some of the shown interfaces. Make sure to study the
existing code before you write your own Worker or
BackendQueueProcessorFactory
implementation.
This section describes in greater detail how to configure the Master/Slave Hibernate Search architecture.
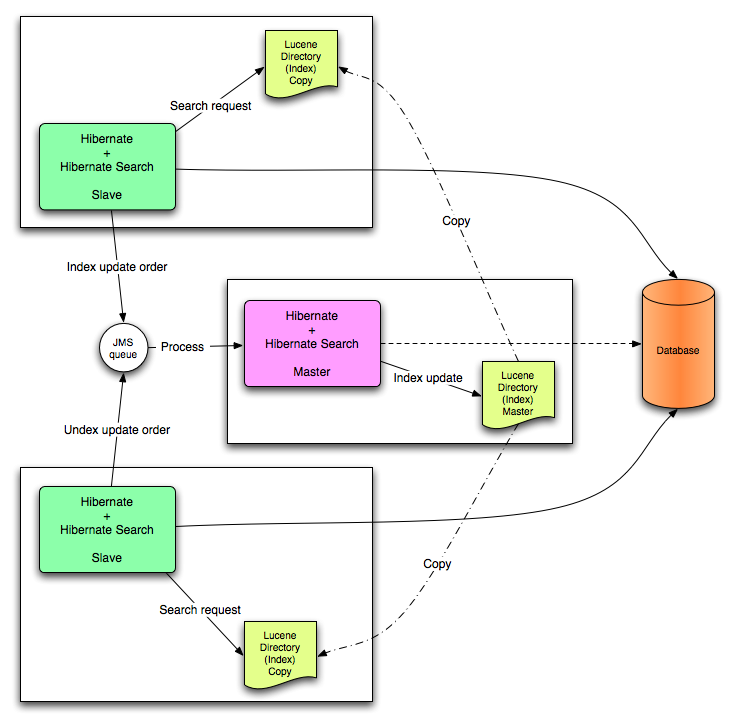
JMS back end configuration.
Every index update operation is sent to a JMS queue. Index querying operations are executed on a local index copy.
Example 3.6. JMS Slave configuration
### slave configuration ## DirectoryProvider # (remote) master location hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local copy location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-slave ## Backend configuration hibernate.search.worker.backend = jms hibernate.search.worker.jms.connection_factory = /ConnectionFactory hibernate.search.worker.jms.queue = queue/hibernatesearch #optional jndi configuration (check your JMS provider for more information) ## Optional asynchronous execution strategy # hibernate.search.worker.execution = async # hibernate.search.worker.thread_pool.size = 2 # hibernate.search.worker.buffer_queue.max = 50
Tip
A file system local copy is recommended for faster search results.
Tip
The refresh period should be higher that the expected copy time.
Every index update operation is taken from a JMS queue and executed. The master index is copied on a regular basis.
Example 3.7. JMS Master configuration
### master configuration ## DirectoryProvider # (remote) master location where information is copied to hibernate.search.default.sourceBase = /mnt/mastervolume/lucenedirs/mastercopy # local master location hibernate.search.default.indexBase = /Users/prod/lucenedirs # refresh every half hour hibernate.search.default.refresh = 1800 # appropriate directory provider hibernate.search.default.directory_provider = filesystem-master ## Backend configuration #Backend is the default lucene one
Tip
The refresh period should be higher that the expected time copy.
In addition to the Hibernate Search framework configuration, a Message Driven Bean has to be written and set up to process the index works queue through JMS.
Example 3.8. Message Driven Bean processing the indexing queue
@MessageDriven(activationConfig = {
@ActivationConfigProperty(propertyName="destinationType",
propertyValue="javax.jms.Queue"),
@ActivationConfigProperty(propertyName="destination",
propertyValue="queue/hibernatesearch"),
@ActivationConfigProperty(propertyName="DLQMaxResent", propertyValue="1")
} )
public class MDBSearchController extends AbstractJMSHibernateSearchController
implements MessageListener {
@PersistenceContext EntityManager em;
//method retrieving the appropriate session
protected Session getSession() {
return (Session) em.getDelegate();
}
//potentially close the session opened in #getSession(), not needed here
protected void cleanSessionIfNeeded(Session session)
}
}
This example inherits from the abstract JMS controller class
available in the Hibernate Search source code and implements a JavaEE 5
MDB. This implementation is given as an example and can be adjusted to
make use of non Java EE Message Driven Beans. For more information about
the getSession() and
cleanSessionIfNeeded(), please check
AbstractJMSHibernateSearchController's
javadoc.
This section describes how to configure the JGroups Master/Slave
back end. The configuration examples illustrated in Section 3.6, “JMS Master/Slave configuration” also apply here, only a different backend
(hibernate.search.worker.backend) needs to be
set.
Every index update operation is sent through a JGroups channel to the master node. Index querying operations are executed on a local index copy.
Example 3.9. JGroups Slave configuration
### slave configuration hibernate.search.worker.backend = jgroupsSlave
Every index update operation is taken from a JGroups channel and executed. The master index is copied on a regular basis.
Example 3.10. JGroups Master configuration
### master configuration hibernate.search.worker.backend = jgroupsMaster
Optionally the configuration for the JGroups transport protocols
and channel name can be defined and applied to master and slave nodes.
There are several ways to configure the JGroups transport details. You
can either set the
hibernate.search.worker.backend.jgroups.configurationFile
property and specify a file containing the JGroups configuration or you
can use the property
hibernate.search.worker.backend.jgroups.configurationXml
or
hibernate.search.worker.backend.jgroups.configurationString
to directly embed either the xml or string JGroups configuration into
your Hibernate configuration file. All three options are shown in Example 3.11, “JGroups transport protocol configuration”.
Tip
If no property is explicitly specified it is assumed that the
JGroups default configuration file flush-udp.xml is
used.
Example 3.11. JGroups transport protocol configuration
## JGroups configuration options
# OPTION 1 - udp.xml file needs to be located in the classpath
hibernate.search.worker.backend.jgroups.configurationFile = udp.xml
# OPTION 2 - protocol stack configuration provided in XML format
hibernate.search.worker.backend.jgroups.configurationXml =
<config xmlns="urn:org:jgroups"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="urn:org:jgroups file:schema/JGroups-2.8.xsd">
<UDP
mcast_addr="${jgroups.udp.mcast_addr:228.10.10.10}"
mcast_port="${jgroups.udp.mcast_port:45588}"
tos="8"
thread_naming_pattern="pl"
thread_pool.enabled="true"
thread_pool.min_threads="2"
thread_pool.max_threads="8"
thread_pool.keep_alive_time="5000"
thread_pool.queue_enabled="false"
thread_pool.queue_max_size="100"
thread_pool.rejection_policy="Run"/>
<PING timeout="1000" num_initial_members="3"/>
<MERGE2 max_interval="30000" min_interval="10000"/>
<FD_SOCK/>
<FD timeout="3000" max_tries="3"/>
<VERIFY_SUSPECT timeout="1500"/>
<pbcast.STREAMING_STATE_TRANSFER/>
<pbcast.FLUSH timeout="0"/>
</config>
# OPTION 3 - protocol stack configuration provided in "old style" jgroups format
hibernate.search.worker.backend.jgroups.configurationString =
UDP(mcast_addr=228.1.2.3;mcast_port=45566;ip_ttl=32):PING(timeout=3000;
num_initial_members=6):FD(timeout=5000):VERIFY_SUSPECT(timeout=1500):
pbcast.NAKACK(gc_lag=10;retransmit_timeout=3000):UNICAST(timeout=5000):
FRAG:pbcast.GMS(join_timeout=3000;shun=false;print_local_addr=true) In this JGroups master/slave configuration nodes communicate over
a JGroups channel. The default channel name is
HSearchCluster which can be configured as seen in
Example 3.12, “JGroups channel name configuration”.
Example 3.12. JGroups channel name configuration
hibernate.search.worker.backend.jgroups.clusterName = Hibernate-Search-Cluster
Infinispan is a distributed scalable, highly available data grid platform which supports autodiscovery of peer nodes. It is possible to store the Lucene index in Infinispan, making it easy to setup a clustering configuration with Hibernate Search and having updates to the index available on other nodes very quickly.
This section describes in greater detail how to configure Hibernate Search to use an Infinispan Lucene Directory.
Using an Infinispan Directory the index is stored in memory and shared across multiple nodes. It is considered a single directory across all participating nodes. If a node updates the index, all other nodes are affected as well. Updates on one node can be immediately searched for in the whole cluster.
The default configuration replicates all data defining the index across all nodes, thus consuming a significant amount of memory. For large indexes it's suggested to enable data distribution, so that each piece of information is replicated to a subset of all cluster members.
It is also possible to offload part or most information to a single
centralized CacheStore, such as plain filesystem,
Amazon S3, Cassandra, Berkley DB, JDBC standard databases. You can also
have a CacheStore on each node or chain cachestores.
See the Infinispan
documentation for all options and configuration details.
Infinispan requires Java 6 and an updated version of JGroups. To use the Infinispan directory via maven, add the following dependencies:
Example 3.13. Maven dependencies for Hibernate Search
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search</artifactId>
<version>3.3.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-search-infinispan</artifactId>
<version>3.3.0.Final</version>
</dependency>
For the non-maven users, add
hibernate-search-infinispan.jar,
infinispan-lucene-directory.jar and
infinispan-core.jar to your application classpath.
These last two jars are distributed by Infinispan.
Also make sure to update JGroups to a version matching the Infinispan
package. The version normally distributed with Hibernate Search is older
to maintain Java 5 compatibility.
Even when using an Infinispan directory it's still recommended to
use the JMS Master/Slave or JGroups backend, because in Infinispan all
nodes will share the same index and it is likely that
IndexWriters being active on different nodes will
try to acquire the lock on the same index. So instead of sending updates
directly to the index, it is recommended to send it to a JMS queue or
JGroups channel and have a single node apply all changes on behalf of
all other nodes.
To configure a JMS slave only the backend must be replaced, the
directory provider must be set to infinispan; set the
same directory provider on the master, they will connect without the
need to setup the copy job across nodes. Using the JGroups backend is
very similar, just combine the backend configuration with the
infinispan directory provider.
To use Infinispan, a CacheManager must be
started from an Infinispan configuration file. Hibernate Search can take
and reuse an existing CacheManager, look it up
via JNDI, or start a new one. In the latter case Hibernate Search will
start and stop it ( closing occurs at
SessionFactory close).
To use and existing CacheManager from JNDI
(optional parameter):
hibernate.search.infinispan.cachemanager_jndiname = [jndiname]
To start a new CacheManager from a
configuration file (optional parameter):
hibernate.search.infinispan.configuration_resourcename = [infinispan configuration filename]
If both parameters are defined, JNDI will have priority. If none
of these is defined, Hibernate Search will use the example Infinispan
configuration provided in the
hibernate-search-infinispan.jar
As mentioned in infinispan configuration in Table 3.1, “List of built-in
DirectoryProviders”, each index actually makes use of
three caches, so three different caches should be configured as shown in
the default-hibernatesearch-infinispan.xml provided
in the hibernate-search-infinispan.jar. Several
indexes can share the same caches, they are differentiated by using the
index name as it is the case with the other Directory
implementations.
The different reader strategies are described in Reader strategy. Out of the box strategies are:
shared: share index readers across several queries. This strategy is the most efficient.not-shared: create an index reader for each individual query
The default reader strategy is shared. This can
be adjusted:
hibernate.search.reader.strategy = not-shared
Adding this property switches to the not-shared
strategy.
Or if you have a custom reader strategy:
hibernate.search.reader.strategy = my.corp.myapp.CustomReaderProvider
where my.corp.myapp.CustomReaderProvider is
the custom strategy implementation.
Hibernate Search allows you to tune the Lucene indexing performance
by specifying a set of parameters which are passed through to underlying
Lucene IndexWriter such as
mergeFactor, maxMergeDocs and
maxBufferedDocs. You can specify these parameters
either as default values applying for all indexes, on a per index basis,
or even per shard.
There are two sets of parameters allowing for different performance
settings depending on the use case. During indexing operations triggered
by database modifications, the parameters are grouped by the
transaction keyword:
hibernate.search.[default|<indexname>].indexwriter.transaction.<parameter_name>
When indexing occurs via FullTextSession.index() or via
a MassIndexer (see Section 6.3, “Rebuilding the whole index”), the used properties are those grouped
under the batch keyword:
hibernate.search.[default|<indexname>].indexwriter.batch.<parameter_name>
If no value is set for a batch value in a
specific shard configuration, Hibernate Search will look at the index
section, then at the default section.
Example 3.14. Example performance option configuration
hibernate.search.Animals.2.indexwriter.transaction.max_merge_docs 10 hibernate.search.Animals.2.indexwriter.transaction.merge_factor 20 hibernate.search.default.indexwriter.batch.max_merge_docs 100
The configuration in Example 3.14, “Example performance option configuration” will result in these
settings applied on the second shard of the Animal
index:
transaction.max_merge_docs= 10batch.max_merge_docs= 100transaction.merge_factor= 20batch.merge_factor= Lucene default
All other values will use the defaults defined in Lucene.
The default for all values is to leave them at Lucene's own default.
The values listed in Table 3.7, “List of indexing performance and behavior properties”
depend for this reason on the version of Lucene you are using. The values
shown are relative to version 2.4. For more information
about Lucene indexing performance, please refer to the Lucene
documentation.
Warning
Previous versions had the batch parameters
inherit from transaction properties. This needs now
to be explicitly set.
Table 3.7. List of indexing performance and behavior properties
| Property | Description | Default Value |
|---|---|---|
hibernate.search.[default|<indexname>].exclusive_index_use | Set to | false (releases locks as soon as
possible) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_buffered_delete_terms | Determines the minimal number of delete terms required before the buffered in-memory delete terms are applied and flushed. If there are documents buffered in memory at the time, they are merged and a new segment is created. | Disabled (flushes by RAM usage) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_buffered_docs | Controls the amount of documents buffered in memory during indexing. The bigger the more RAM is consumed. | Disabled (flushes by RAM usage) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_field_length | The maximum number of terms that will be indexed for a single field. This limits the amount of memory required for indexing so that very large data will not crash the indexing process by running out of memory. This setting refers to the number of running terms, not to the number of different terms. This silently truncates large documents, excluding from the index all terms that occur further in the document. If you know your source documents are large, be sure to set this value high enough to accommodate the expected size. If you set it to Integer.MAX_VALUE, then the only limit is your memory, but you should anticipate an OutOfMemoryError. If setting this value in | 10000 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].max_merge_docs | Defines the largest number of documents allowed in a segment. Larger values are best for batched indexing and speedier searches. Small values are best for transaction indexing. | Unlimited (Integer.MAX_VALUE) |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].merge_factor | Controls segment merge frequency and size. Determines how often segment indexes are merged when insertion occurs. With smaller values, less RAM is used while indexing, and searches on unoptimized indexes are faster, but indexing speed is slower. With larger values, more RAM is used during indexing, and while searches on unoptimized indexes are slower, indexing is faster. Thus larger values (> 10) are best for batch index creation, and smaller values (< 10) for indexes that are interactively maintained. The value must no be lower than 2. | 10 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].ram_buffer_size | Controls the amount of RAM in MB dedicated to document buffers. When used together max_buffered_docs a flush occurs for whichever event happens first. Generally for faster indexing performance it's best to flush by RAM usage instead of document count and use as large a RAM buffer as you can. | 16 MB |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].term_index_interval | Expert: Set the interval between indexed terms. Large values cause less memory to be used by IndexReader, but slow random-access to terms. Small values cause more memory to be used by an IndexReader, and speed random-access to terms. See Lucene documentation for more details. | 128 |
hibernate.search.[default|<indexname>].indexwriter.[transaction|batch].use_compound_file | The advantage of using the compound file format is that
less file descriptors are used. The disadvantage is that indexing
takes more time and temporary disk space. You can set this
parameter to false in an attempt to improve the
indexing time, but you could run out of file descriptors if
mergeFactor is also large.Boolean
parameter, use " | true |
Tip
When your architecture permits it, always set
hibernate.search.default.exclusive_index_use=true as
it greatly improves efficiency in index writing.
Tip
To tune the indexing speed it might be useful to time the object
loading from database in isolation from the writes to the index. To
achieve this set the blackhole as worker backend and
start you indexing routines. This backend does not disable Hibernate
Search: it will still generate the needed changesets to the index, but
will discard them instead of flushing them to the index. In contrast to
setting the hibernate.search.indexing_strategy to
manual, using blackhole will
possibly load more data from the database. because associated entities
are re-indexed as well.
hibernate.search.worker.backend blackhole
The recommended approach is to focus first on optimizing the object loading, and then use the timings you achieve as a baseline to tune the indexing process.
Warning
The blackhole backend is not meant to be used
in production, only as a tool to identify indexing bottlenecks.
Lucene Directorys have default locking
strategies which work well for most cases, but it's possible to specify
for each index managed by Hibernate Search which
LockingFactory you want to use.
Some of these locking strategies require a filesystem level lock and may be used even on RAM based indexes, but this is not recommended and of no practical use.
To select a locking factory, set the
hibernate.search.<index>.locking_strategy option
to one of simple, native,
single or none. Alternatively set it
to the fully qualified name of an implementation of
org.hibernate.search.store.LockFactoryFactory.
Table 3.8. List of available LockFactory implementations
| name | Class | Description |
|---|---|---|
| simple | org.apache.lucene.store.SimpleFSLockFactory | Safe implementation based on Java's File API, it marks the usage of the index by creating a marker file. If for some reason you had to kill your application, you will need to remove this file before restarting it. This is the default implementation for the
|
| native | org.apache.lucene.store.NativeFSLockFactory | As does This implementation has known problems on NFS. |
| single | org.apache.lucene.store.SingleInstanceLockFactory | This LockFactory doesn't use a file marker but is a Java object lock held in memory; therefore it's possible to use it only when you are sure the index is not going to be shared by any other process. This is the default implementation for
the |
| none | org.apache.lucene.store.NoLockFactory | All changes to this index are not coordinated by any lock; test your application carefully and make sure you know what it means. |
Configuration example:
hibernate.search.default.locking_strategy simple hibernate.search.Animals.locking_strategy native hibernate.search.Books.locking_strategy org.custom.components.MyLockingFactory
Hibernate Search allows you to configure how exceptions are handled during the indexing process. If no configuration is provided then exceptions are logged to the log output by default. It is possible to explicitly declare the exception logging mechanism as seen below:
hibernate.search.error_handler log
The default exception handling occurs for both synchronous and asynchronous indexing. Hibernate Search provides an easy mechanism to override the default error handling implementation.
In order to provide your own implementation you must implement the
ErrorHandler interface, which provides the
handle(ErrorContext context) method.
ErrorContext provides a reference to the primary
LuceneWork instance, the underlying exception and any
subsequent LuceneWork instances that could not be processed
due to the primary exception.
public interface ErrorContext {
List<LuceneWork> getFailingOperations();
LuceneWork getOperationAtFault();
Throwable getThrowable();
boolean hasErrors();
} To register this error handler with Hibernate Search you must
declare the fully qualified classname of your
ErrorHandler implementation in the configuration
properties:
hibernate.search.error_handler CustomerErrorHandler