There are a lot of ways for applications to store information persistently so that it can be accessed at a later time and by other processes. The challenge developers face is how to use an approach that most closely matches the needs of their application. This choice becomes more important as developers choose to focus their efforts on application-specific logic, delegating much of the responsibilities for persistence to libraries and frameworks.
Perhaps one of the easiest techniques is to simply store information in files . The Java language makes working with files relatively easy, but Java really doesn't provide many bells and whistles. So using files is an easy choice when the information is either not complicated (for example property files), or when users may need to read or change the information outside of the application (for example log files or configuration files). But using files to persist information becomes more difficult as the information becomes more complex, as the volume of it increases, or if it needs to be accessed by multiple processes. For these situations, other techniques often have more benefits.
Another technique built into the Java language is Java serialization , which is capable of persisting the state of an object graph so that it can be read back in at a later time. However, Java serialization can quickly become tricky if the classes are changed, and so it's beneficial usually when the information is persisted for a very short period of time. For example, serialization is sometimes used to send an object graph from one process to another. Using serialization for longer-term storage of information is more risky.
One of the more popular and widely-used persistence technologies is the relational database. Relational database management systems have been around for decades and are very capable. The Java Database Connectivity (JDBC) API provides a standard interface for connecting to and interacting with relational databases. However, it is a low-level API that requires a lot of code to use correctly, and it still doesn't abstract away the DBMS-specific SQL grammar. Also, working with relational data in an object-oriented language can feel somewhat unnatural, so many developers map this data to classes that fit much more cleanly into their application. The problem is that manually creating this mapping layer requires a lot of repetitive and non-trivial JDBC code.
Object-relational mapping libraries automate the creation of this mapping layer and result in far less code that is much more maintainable with performance that is often as good as (if not better than) handwritten JDBC code. The new Java Persistence API (JPA) provide a standard mechanism for defining the mappings (through annotations) and working with these entity objects. Several commercial and open-source libraries implement JPA, and some even offer additional capabilities and features that go beyond JPA. For example, Hibernate is one of the most feature-rich JPA implementations and offers object caching, statement caching, extra association mappings, and other features that help to improve performance and usefulness. Plus, Hibernate is open-source (with support offered by JBoss).
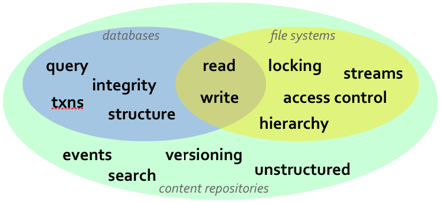
While relational databases and JPA are solutions that work well for many applications, they are more limited in cases when the information structure is highly flexible, the structure is not known a priori, or that structure is subject to frequent change and customization. In these situations, content repositories may offer a better choice for persistence. Content repositories are almost a hybrid with the storage capabilities of relational databases and the flexibility offered by other systems, such as using files. Content repositories also typically provide other capabilities as well, including versioning, indexing, search, access control, transactions, and observation. Because of this, content repositories are used by content management systems (CMS), document management systems (DMS), and other applications that manage electronic files (e.g., documents, images, multi-media, web content, etc.) and metadata associated with them (e.g., author, date, status, security information, etc.). The Content Repository for Java technology API provides a standard Java API for working with content repositories. Abbreviated "JCR", this API was developed as part of the Java Community Process under JSR-170 and is being revised under JSR-283.
The JCR API provides a number of information services that are needed by many applications, including: read and write access to information; the ability to structure information in a hierarchical and flexible manner that can adapt and evolve over time; ability to work with unstructured content; ability to (transparently) handle large strings; notifications of changes in the information; search and query; versioning of information; access control; integrity constraints; participation within distributed transactions; explicit locking of content; and of course persistence.
What makes JCR interesting, however, is that a JCR implementation provides all these features and capabilities regardless of where or how that information is persisted or stored. This is in fact the main purpose of JBoss DNA: provide a JCR implementation that provides access to content stored in many different kinds of systems. A JBoss DNA repository isn't yet another silo of information, but rather it's a JCR view of the information you already have in your environment: files systems, databases, other repositories, services, applications, etc. JBoss DNA can help you understand the systems and information you already have.
Of course when you start providing a unified view of all this information, you start recognizing the need to store more information, including metadata about and relationships between the existing content. JBoss DNA lets you do this, too. And JBoss DNA even tries to help you discover more about the information you already have, especially the information wrapped up in the kinds of files often found in enterprise systems: service definitions, policy files, images, media, documents, presentations, application components, reusable libraries, configuration files, application installations, databases schemas, management scripts, and so on. As files are loaded into the repository, JBoss DNA can sequence these files to extract from their content meaningful information that can be stored in the repository, where your applications can find it by using the standard JCR API to search, access, and use the information.
So, JBoss DNA is a JCR implementation that can automatically sequence files loaded into the repository, and it can be used as a traditional JCR silo repository. But it can also let your applications use the JCR API to access the content in other systems, and can unify the content from multiple external systems and multiple storage systems to provide a single, federated repository.
As we'll see in the next chapter, the ability of JBoss DNA to
federate, integrate, and sequence information make JBoss DNA a powerful asset and tool.
Then Chapter 3 will show that once a JBoss DNA repository is set up, applications see
JBoss DNA just as another JCR javax.jcr.Repository instance and use the standard JCR API to obtain a javax.jcr.Session
and work with the content.
Chapter 4 walks you through downloading and building the JBoss DNA examples, while Chapter 5 and Chapter 6 will run these very simple examples and walk through their code. Chapter 7 wraps things up with a discussion about the future of JBoss DNA and what you can do next to start using JBoss DNA in your own applications.