Chapter 4 walked through the process of downloading and building the examples, while the previous chapter showed how to run the sequencer example and walked through the code. In this chapter, we'll run the repository example and walk through that example code to see what it's doing.
The repository example consists of a client application that sets up three DNA repositories (named "Cars", "Airplanes", and "UFOs") and a federated repository ("Vehicles") that dynamically federates the information from the other three repositories. The client application allows you to interactively navigate each of these repositories just as you would navigate the directory structure on a file system.
This collection of repositories is shown in the following figure:
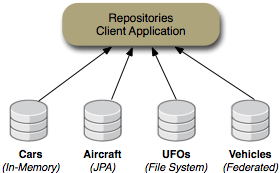
The "Cars" repository is an in-memory repository (using the In-Memory repository connector), the "Aircraft" repository is a JPA repository
(using an in-memory HSQL database using the JPA repository connector), and the "UFOs" repository is
a file system repository (using the File System repository connector). The federated "Vehicles" repository
content is federated from the other repositories and cached into the "Cache" repository. This is shown in the following figure:
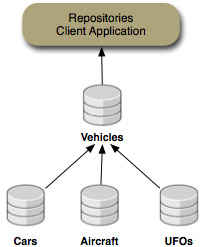
Figure 6.2. Vehicles repository content is federated from the Cars, Airplanes, UFOs, and Configuration repositories
To run the client application, go to the examples/repository/target/dna-example-repositories-basic.dir/
directory and type ./run.sh. You should see the command-line client and its menus in your terminal:
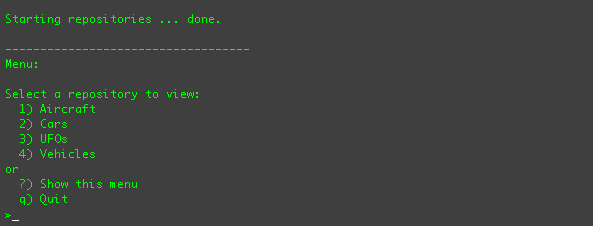
From this menu, you can see the list of repositories, select one, and navigate through that repository in a manner similar
to a *nix command-line shell (although the client itself uses the JCR API to interact with the repositories).
Here are some of the commands you can use:
Table 6.1. Repository client commands to navigate a repository
| Command | Description |
|---|---|
| pwd | Print the path of the current node (e.g., the "working directory") |
| ls [path] | List the children and properties of the node at the supplied path, where "path" can be any relative path or absolute path. If "path" is not supplied, the current working node's path is used. |
| cd path | Change to the specified node, where "path"
can be any relative path or absolute path. For example, "cd alpha" changes the current node to be a child named
"alpha"; "cd .." changes the current node to the parent node; "cd /a/b" changes
the current node to be the "/a/b" node. |
| exit | Exit this repository and return the list of repositories. |
Note
The first time you access any repository, the application is automatically logging you in to DNA's JAAS-based security system. To make the application easier to use, it always logs in with the "jsmith" as the username and "secret" as the password. This matches what is configured in the "jaas.conf.xml" and "users.properties" files. If you want to confirm that the security feature is working, change the password in target/dna-example-repositories-basic.dir/users.properties to something else and re-run the application. After you select a repository and try to view a directory with 'ls', you will get a LoginException!
If you were to select the "Cars" repository and use some of the commands, you should see something similar to:
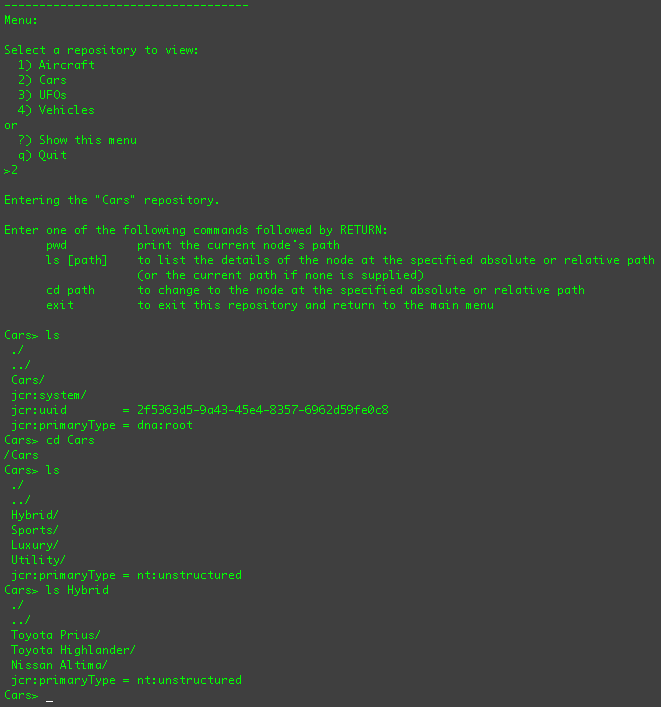
You can also choose to navigate the "Vehicles" repository, which projects the "Cars" repository content under the
/Vehicles/Cars node, the "Airplanes" content under the /Vehicles/Airplanes branch,
the "UFOs" content under the /Vehicles/UFOs branch,
and the "Configuration" content under /dna:system.
Try using the client to walk the different repositories. And while this is a contrived application, it does demonstrate the use of JBoss DNA to federate repositories and provide access through JCR.
As mentioned in the Introduction, one of the capabilities of JBoss DNA is to provide access through JCR to different kinds of repositories and storage systems. Your applications work with the JCR API, but through JBoss DNA you're able to accesses the content from where the information exists - not just a single purpose-built repository. This is fundamentally what makes JBoss DNA different.
How does JBoss DNA do this? At the heart of JBoss DNA and it's JCR implementation is a simple connector system that is designed around creating and accessing graphs. The JBoss DNA JCR implementation actually just sits on top of a single repository source, which it uses to access of the repositories content.
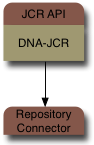
That single repository connector could access:
a transient, in-memory repository
an Infinispan data grid that acts as an extremely scalable, highly-available store for repository content
a JBoss Cache instance that acts as a clustered and replicated store for repository content
a JDBC database used as a store for repository content
a repository that accesses existing JDBC databases to project the schema structure as read-only repository content
a repository that accesses a file systems to present the files and directory structure as (updatable) repository content
a repository that accesses an SVN repository to present the files and directory structure as (updatable) repository content
a federated repository that presents a unified, updatable view of the content in multiple other systems (which are accessed via connectors)
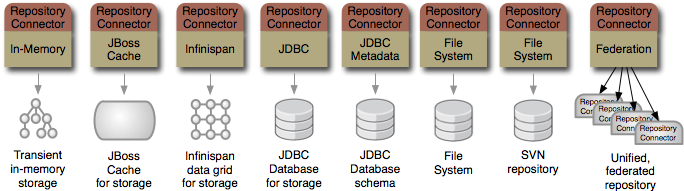
And the JBoss DNA project has plans to create other connectors, too. For instance, we're going to build a connector
to other JCR repositories. And another to access existing databases so that some or all of the existing data (in whatever structure)
can be accessed through JCR. Of course, if we don't have a connector to suit your needs, you can write your own.
Note
You might be thinking that these connectors are interesting, but what do they really provide? Is it really useful to use JCR to access a relational database rather than JDBC? Or, why access the files on a file system when there are already mechanisms to do that?
Maybe putting JCR on top of a single system (like a JDBC database) isn't that interesting. What is interesting, though, is accessing the information in multiple systems as if all that information were in a single JCR repository. That's what the federated repository source is all about. The JBoss DNA connector system just makes it possible to interact with all these systems in the same way.
Think of it this way: with JBoss DNA, you can use JCR to get to the schemas of multiple relational databases and the schemas defined by DDL files in your SVN repository and the schemas defined by logical models stored on your file system.
Before we go further, let's define some terminology regarding connectors.
A connector is the runnable code packaged in one or more JAR files that contains implementations of several interfaces (described below). A Java developer writes a connector to a type of source, such as a particular database management system, LDAP directory, source code management system, etc. It is then packaged into one or more JAR files (including dependent JARs) and deployed for use in applications that use JBoss DNA repositories.
The description of a particular source system (e.g., the "Customer" database, or the company LDAP system) is called a repository source. JBoss DNA defines a RepositorySource interface that defines methods describing the behavior and supported features and a method for establishing connections. A connector will have a class that implements this interface and that has JavaBean properties for all of the connector-specific properties required to fully describe an instance of the system. Use of JavaBean properties is not required, but it is highly recommended, as it enables reflective configuration and administration. Applications that use JBoss DNA create an instance of the connector's RepositorySource implementation and set the properties for the external source that the application wants to access with that connector.
A repository source instance is then used to establish connections to that source. A connector provides an implementation of the RepositoryConnection interface, which defines methods for interacting with the external system. In particular, the
execute(...)method takes anExecutionContextinstance and aRequestobject. The object defines the environment in which the processing is occurring, including information about the JAASSubjectandLoginContext. TheRequestobject describes the requested operations on the content, with different concrete subclasses representing each type of activity. Examples of commands include (but not limited to) getting a node, moving a node, creating a node, changing a node, and deleting a node. And, if the repository source is able to participate in JTA/JTS distributed transactions, then the RepositoryConnection must implement thegetXaResource()method by returning a validjavax.transaction.xa.XAResourceobject that can be used by the transaction monitor.
As an example, consider that we want JBoss DNA to give us access through JCR to the schema information contained in a
relational database. We first have to develop a connector that allows us to interact with relational databases using JDBC.
That connector would contain a JdbcMetadataSource Java class that implements RepositorySource,
and that has all of the various JavaBean properties for setting the name of the driver class, URL, username, password,
and other properties. If we add a JavaBean property defining the JNDI name, our connector could look in JNDI to find a JDBC
DataSource instance, perhaps already configured to use connection pools.
Note
Of course, before you develop a connector, you should probably check the list of connectors JBoss DNA already provides out of the box. With this latest release, JBoss DNA already includes this JDBC metadata connector! And we're always interested in new connectors and new contributors, so please consider developing your custom connector as part of JBoss DNA.
So with this very high-level summary, let's dive a little deeper and look at the repository example.
Recall that the example repository application consists of a client application that sets up a repository service and the repositories defined in a configuration repository, allowing the user to pick a repository and interactively navigate the selected repository. Several repositories are set up, including several standalone repositories and one federated repository that dynamically federates the content from the other repositories.
The example is comprised of 2 classes and 1 interface, located in the src/main/java directory:
org/jboss/example/dna/repositories/ConsoleInput.java
/RepositoryClient.java
/UserInterface.java
RepositoryClient is the class that contains the main application. It uses an instance of the
UserInterface interface to methods that will be called at runtime to obtain information about the
files that are imported into the standalone repositories and the JAAS CallbackHandler implementation
that will be used by JAAS to collect the authentication information. Finally, the ConsoleInput
is an implementation of this that creates a text user interface, allowing the user to operate the client from the command-line.
We can easily create a graphical implementation of UserInterface at a later date, or we can also create a mock
implementation for testing purposes that simulates a user entering data. This allows us to check the behavior of the client
automatically using conventional JUnit test cases, as demonstrated by the code in the src/test/java directory:
org/jboss/example/dna/sequencers/RepositoryClientTest.java
/RepositoryClientUsingJcrTest.java
If we look at the RepositoryClient code, there are a handful of methods that encapsulate the various activities.
Note
Some of the code samples included in this book have had some of the error handling and comments removed so that the code is more readable and concise.
The main(String[] argv) method is of course the method that is executed when the application is run. This code
creates the JBoss DNA configuration by loading it from a file.
// Set up the JAAS provider (IDTrust) and a policy file (which defines the "dna-jcr" login config name)
IDTrustConfiguration idtrustConfig = new IDTrustConfiguration();
try {
idtrustConfig.config("security/jaas.conf.xml");
} catch (Exception ex) {
throw new IllegalStateException(ex);
}
// Now configure the repository client component ...
RepositoryClient client = new RepositoryClient();
for (String arg : args) {
arg = arg.trim();
if (arg.equals("--api=jcr")) client.setApi(Api.JCR);
if (arg.equals("--api=dna")) client.setApi(Api.DNA);
if (arg.equals("--jaas")) client.setJaasContextName(JAAS_LOGIN_CONTEXT_NAME);
if (arg.startsWith("--jaas=") && arg.length() > 7) client.setJaasContextName(arg.substring(7).trim());
}
// And have it use a ConsoleInput user interface ...
client.setUserInterface(new ConsoleInput(client, args));
The first block sets up the JAAS provider to be the IDTrust library and a policy file that defines the "dna-jcr" JAAS configuration.
The second block of code instantiates the RepositoryClient and passes in some options determined from the command-line.
It then sets the user interface (which then executes its behavior, which we'll see below).
The startRepositories() method builds the JcrEngine component from the configuration, starts the engine,
and obtains the JCR javax.jcr.Repository instance that the client will use. Note that the client has not yet
obtained a javax.jcr.Session instance, since this will be done each time the client needs to access content from
the repository. (This is actually a common practice according to the JCR specification, since Sessions are lightweight.)
public void startRepositories() throws IOException, SAXException {
if (engine != null) return; // already started
// Load the configuration from a file, as provided by the user interface ...
JcrConfiguration configuration = new JcrConfiguration();
configuration.loadFrom(userInterface.getRepositoryConfiguration());
// Load the node types for each JCR repository, via a CND file. These could have been defined
// in the configuration file, but this approach is easy and allows us to define the node types
// using the CND format in one or multiple files.
String locationOfCndFiles = userInterface.getLocationOfCndFiles();
configuration.repository("Aircraft").addNodeTypes(locationOfCndFiles + "/aircraft.cnd");
configuration.repository("Cars").addNodeTypes(locationOfCndFiles + "/cars.cnd");
configuration.repository("Vehicles").addNodeTypes(locationOfCndFiles + "/vehicles.cnd");
// Now create the JCR engine ...
engine = configuration.build();
engine.start();
...
// For this example, we're using a couple of in-memory repositories (including one for the
// configuration repository). Normally, these would exist already and would simply be accessed.
// But in this example, we're going to populate these repositories here by importing from files.
// First do the configuration repository ...
String location = this.userInterface.getLocationOfRepositoryFiles();
// Now import the content for the two in-memory repositories ...
Graph cars = engine.getGraph("Cars");
cars.importXmlFrom(location + "/cars.xml").into("/");
Graph aircraft = engine.getGraph("Aircraft");
aircraft.importXmlFrom(location + "/aircraft.xml").into("/");
}
This method does a number of different things. First, it checks to make sure the repositories are not already running; if so
the method just returns. Then, it creates a JBoss DNA JcrConfiguration instance and loads the configuration
from a file provided by the user interface. The method then loads the node types for each of the repositories; this could
have been done in the configuration, but it would have made the configuration file larger and more difficult to understand.
It then creates the JcrEngine from the configuration and starts it. Finally, it obtains the location of the
content files from the user interface, and imports them into the "Cars" and "Aircraft" repositories. Again, this is
done to keep the example simple.
The shutdown() method of the example then logs out and requests that the JcrEngine instance
shut down and, since that may take
a few moments (if there are any ongoing operations or enqueued activities) awaits for it to complete the shutdown.
public void shutdown() throws InterruptedException, LoginException {
logout();
if (engine == null) return;
try {
// Tell the engine to shut down, and then wait up to 5 seconds for it to complete...
engine.shutdown();
engine.awaitTermination(5, TimeUnit.SECONDS);
} finally {
engine = null;
}
}
A few of the other methods in the RepositoryClient class deal with the JAAS LoginContext.
When needed, the client will authenticate the user (by asking the user interface for a callback handler that will be called
when the authentication information is needed). The resulting authenticated LoginContext is wrapped
by a custom javax.jcr.Credentials implementation. As long as the Credentials implementation
has a getLoginContext() method that returns a LoginContext object, JBoss DNA's repository
implementation will use that context to create the javax.jcr.Session. (Of course, the javax.jcr.SimpleCredentials
can also be used to create a Session, and JBoss DNA will then attempt to use JAAS to authenticate the user given by the credentials.)
The getNodeInfo(...) method of the example is what is called when the properties and children of a particular node
are requested by the user interface. (In the console user interface, this happens when the user navigates the graph structure.)
There are really two different behaviors to this method, depending upon whether the JCR API is to be used or whether
the JBoss DNA Graph API is to be used. The portion that uses JCR is shown below:
JcrRepository jcrRepository = engine.getRepository(sourceName);
Session session = null;
if (loginContext != null) {
// Could also use SimpleCredentials(username,password) too
Credentials credentials = new JaasCredentials(loginContext);
session = jcrRepository.login(credentials);
} else {
session = jcrRepository.login();
}
try {
// Make the path relative to the root by removing the leading slash(es) ...
pathToNode = pathToNode.replaceAll("^/+", "");
// Get the node by path ...
Node root = session.getRootNode();
Node node = root;
if (pathToNode.length() != 0) {
if (!pathToNode.endsWith("]")) pathToNode = pathToNode + "[1]";
node = pathToNode.equals("") ? root : root.getNode(pathToNode);
}
// Now populate the properties and children ...
if (properties != null) {
for (PropertyIterator iter = node.getProperties(); iter.hasNext();) {
javax.jcr.Property property = iter.nextProperty();
Object[] values = null;
// Must call either 'getValue()' or 'getValues()' depending upon # of values
if (property.getDefinition().isMultiple()) {
Value[] jcrValues = property.getValues();
values = new String[jcrValues.length];
for (int i = 0; i < jcrValues.length; i++) {
values[i] = jcrValues[i].getString();
}
} else {
values = new Object[] {property.getValue().getString()};
}
properties.put(property.getName(), values);
}
}
if (children != null) {
// Figure out which children need same-name sibling indexes ...
Set<String> sameNameSiblings = new HashSet<String>();
for (NodeIterator iter = node.getNodes(); iter.hasNext();) {
javax.jcr.Node child = iter.nextNode();
if (child.getIndex() > 1) sameNameSiblings.add(child.getName());
}
for (NodeIterator iter = node.getNodes(); iter.hasNext();) {
javax.jcr.Node child = iter.nextNode();
String name = child.getName();
if (sameNameSiblings.contains(name)) name = name + "[" + child.getIndex() + "]";
children.add(name);
}
}
} catch (javax.jcr.ItemNotFoundException e) {
return false;
} catch (javax.jcr.PathNotFoundException e) {
return false;
} finally {
if (session != null) session.logout();
}
This code is literally just using the standard JCR API. First, it obtains a javax.jcr.Session instance
(using the available LoginContext), finds the desired javax.jcr.Node, copies the
properties and names of the children into collections supplied by the caller via method parameters, and
finally logs out of the session.
The JBoss DNA Graph API is actually an internal API used within the different components of JBoss DNA
(including the connector and sequencer frameworks), and provides low-level access to the exact same content.
Though we do not recommend using this API in your client applications, if you need to write a connector
or sequencer, you may need to know how to use the Graph API.
Here is the portion of the getNodeInfo(...) method that does the exact same operation as the JCR code
shown above:
// Use the DNA Graph API to read the properties and children of the node ...
ExecutionContext context = loginContext != null ? this.context.create(loginContext) : this.context;
Graph graph = engine.getGraph(context, sourceName);
graph.useWorkspace("default");
org.jboss.dna.graph.Node node = graph.getNodeAt(pathToNode);
if (properties != null) {
// Now copy the properties into the map provided as a method parameter ...
for (Property property : node.getProperties()) {
String name = property.getName().getString(context.getNamespaceRegistry());
properties.put(name, property.getValuesAsArray());
}
}
if (children != null) {
// And copy the names of the children into the list provided as a method parameter ...
for (Location child : node.getChildren()) {
String name = child.getPath().getLastSegment().getString(context.getNamespaceRegistry());
children.add(name);
}
}
Note that this code is significantly shorter than the equivalent code based upon the JCR API. This is in part because the Graph API doesn't have the notion of a stateful session. But some of it also is simply because the Graph API design requires less code to do the same kinds of operations.
None of the other methods in the RepositoryClient really do anything with JBoss DNA or JCR
per se. Instead, they really facilitate interaction with the user interface.
If we look at the ConsoleInput constructor, it starts the repository and a thread
for the user interface. At this point, the constructor returns, but the main application continues under the user interface thread.
When the user requests to quit, the user interface thread also shuts down the JCR repository.
public ConsoleInput( SequencerClient client ) {
try {
client.startRepositories();
System.out.println(getMenu());
Thread eventThread = new Thread(new Runnable() {
private boolean quit = false;
public void run() {
try {
while (!quit) {
// Display the prompt and process the requested operation ...
}
} finally {
try {
// Terminate ...
client.shutdown();
} catch (Exception err) {
System.out.println("Error shutting down repository: "
+ err.getLocalizedMessage());
err.printStackTrace(System.err);
}
}
}
});
eventThread.start();
} catch (Exception err) {
System.out.println("Error: " + err.getLocalizedMessage());
err.printStackTrace(System.err);
}
}
At this point, we've reviewed all of the interesting code in the example application related to JBoss DNA. However, feel free to play with the application, trying different things.
This chapter walked through running the repository example and looked at the example code. This example allowed you to walk through multiple repositories, including one whose content was federated from multiple other repositories. This was a very simplistic example that only took a few minutes to run.
In the next chapter we'll wrap up by summarizing what we've learned about JBoss DNA and provide information about where you can find out more about JBoss DNA.