J2EE (Java 2 Enterprise Edition) was first introduced to the world by Sun Microsystems in 1999. Its primary focus is for developing distributed and loosely coupled middleware applications. Those applications typically have a web front end and a relational database backend. As web applications become popular in recent years, J2EE has gained wide acceptance among developers. In fact, J2EE is one of the few dominant web application platforms today.
However, as J2EE is more widely used, developers are also increasingly frustrated by its complexities. The original design of J2EE addresses the distributed computing problems and application scalability problems that only the biggest enterprises encounter. As important as those problems are, most developers use J2EE to develop small to middle sized web applications. Those "enterprise features" not only are of limited use but also add unnecessary complexity to otherwise simple web applications. To make matter worse, the default architecture of J2EE applications is inherently inefficient for small web sites even if the developer can get through the initial learning curve for the API and the framework. That has resulted in many late and difficult to manage projects and given J2EE a bad name. The problems have grown as J2EE has evolved and added more features to address a wider range of enterprise use cases.
In order to make enterprise Java more appealing to majority of developers who work with small web applications, the Java community has made major efforts to simplify Java web and middleware frameworks. From the early efforts of the Spring and Hibernate frameworks to the infusion of Aspect Oriented Programming (AOP) techniques and annotation-based metedata, various lightweight enterprise Java frameworks have been developed in the past 3 years. Those new frameworks preserve the power and flexibility of J2EE and make application development much easier and faster. The Java EE 5 specifications standardizes the innovations of those proprietary lightweight frameworks , providing a simpler development model for all Java EE developers. In this book, we will discuss how developers can reap the benefits of those exciting new developments.
The J2EE name and version change
The enterprise Java specification after J2EE 1.4 is called Java EE 5.0. This change highlights the significant changes lightweight frameworks brought to the enterprise Java standards.
The J2EE 1.4 specification, released in 2004, is the last version of heavyweight J2EE. Although this book focuses on lightweight enterprise Java frameworks after J2EE 1.4, those lightweight frameworks have their roots in older J2EE and they borrow heavily from proven concepts from J2EE 1.4. So, it is a good exercise for us to discuss the true "spirit" of J2EE.
A typical J2EE web application has servlets that take in user input and generate the response by displaying JavaServer Pages. The servlet delegates business operations and database-related work to an EJB (Enterprise JavaBeans) module containing session bean objects and entity bean objects. The stateless session bean typically contains transactional methods to perform business operations. Those methods are exposed to the servlet. The session bean makes use of entity beans to access the relational database. In the XML configuration files, we define how to use container services (e.g., transactions and security) from the session beans, as well as how the entity beans are mapped to database tables. Figure 1.1, “Architecture of a J2EE 1.4 web application” shows the above-described architecture. Since the EJB managed components cannot be serialized out of the container, we have to use value objects to exchange data across the layers (i.e., method call parameters and return values).
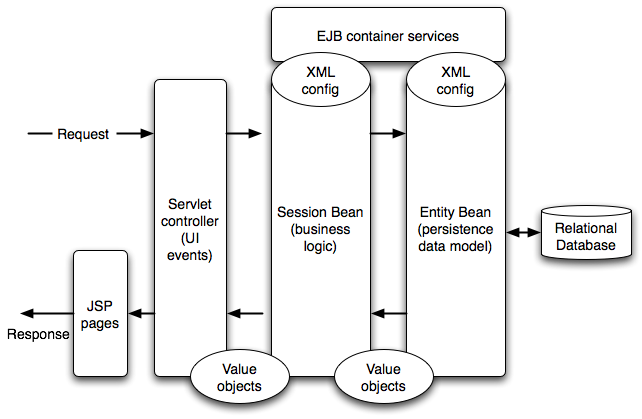
At the first glance, the J2EE architecture looks convoluted. But all the J2EE components work together to serve a common purpose -- to make the application more scalable. Below is a list of key architectural characteristics that makes J2EE great.
Component-based architecture: J2EE components are advanced forms of Java objects. Each component completely encapsulates its own code, configuration, and outward interface. The entire application can be composed from a set of reusable components. Those components can reside on a single computer or on a network of computers to improve application scalability. As we will see in the next several bullet items, components make the application simpler and easier to maintain.
Loose coupling between components: When J2EE components make method calls against another component (e.g., the servlet calls a method in the session bean), the caller component never instantiates the callee component. Instead, the caller requests a reference (or "stub") to the callee from the container using the callee's interface. The container manages all the object creation and the components are only coupled by interfaces. The benefit is that when we change a component implementation, the effect of the change would not ripple out of the component itself as long as we keep its published interface stable.
Shared services provided by the container: The J2EE container provides common application services, such as transaction management, network connection pools, access security, data persistence, and logging, to the components. That allows the application to focus on the business logic.
Declarative configuration: In J2EE, you can simply configure how the container service is delivered to your components using XML configuration files. The use of metadata to configure services reduces the clutter in the code and makes J2EE components easier to maintain.
A complete Object Relational Mapping (ORM) solution: You can use J2EE entity beans to model application data stored in a backend relational databases. That allows you to operate on Java objects instead of dealing with the relational model via SQL statements. The details of vendor-dependent SQL statements are generated by the container and are completely transparent to the application developer.
While those architectural characteristics are crucial for the success of J2EE, their implementations are not always sensible. In fact, in J2EE 1.4 and earlier, the implementation is unnecessarily complex for developers. In the next section, let's discuss the lessons we learned from J2EE 1.4, especially from EJB 2.1. We what a successful lightweight enterprise Java framework should look like while still preserving the J2EE way.
The "lightweight" component approach was originally proposed to counter the "heavyweight" approach in EJB 2.1. EJB 2.1 is the core business component framework in J2EE 1.4, and it is notoriously hard to use. So, to understand what qualifies as a "lightweight" framework, we have to discuss it in the context of "what is wrong with EJB 2.1". If you have never used EJB 2.1 before, then it is probably safe to skim through the headlines in this section and then move on to the next section to learn the lightweight frameworks in JBoss.
However, if you are indeed from the EJB 2.1 land, this section could serve as a useful introduction to lightweight technologies. We will use the next generation of EJB (EJB 3.0, hereafter EJB3) as an example and contrast it with EJB 2.1. EJB3 is core to Java EE 5.0, and is an industry-wide effort to standardize a lightweight framework for Java enterprise developers. EJB3 looks almost completely different from EJB 2.1, yet it captures the flexibility and power of the J2EE way.
J2EE 1.4 has a very rigid component structure. In the EJB 2.1 specification, the beans have to inherit from certain framework classes and implement multiple framework interfaces. Those abstract base classes and interfaces act as the "hook" between the bean and the container. For instance, the container would register classes that implement the javax.ejb.EJBObject interface as EJBs; EJB classes that also implement the java.rmi.Remote interface would be made accessible over the network; when instantiating the EJB, the container would also call the ejbCreate() method in the bean class, which is declared in the bean's abstract base class javax.ejb.SessionBean. You have to implement the life cycle methods (e.g., the ejbCreate() method) in the abstract base class even if they are empty.
The rigid component structure makes it difficult to inherit from EJB 2.1 beans. It essentially forces developers back to use pre-Java procedural programming techniques in J2EE applications. In addition, you cannot directly pass EJB 2.1 beans across J2EE tiers. You have to write special serializable "data transfer objects" (DTOs, also known as value objects) to clone the data content inside the bean. That is a lot of duplicated code.
A much better solution is to use plain old Java objects (POJOs) as service components. However, without the underlying framework interfaces and abstract classes acting as "hooks", how does the framework know which POJO is a managed EJB component?
The container manages the POJOs according to configuration metadata associated with the Java objects. For instance, the metadata could specify which bean methods are the life cycle methods and eliminate the need for the abstract base class. The POJO approach is a cornerstone of lightweight frameworks. In some POJO frameworks, the metadata is completely specified in separate XML files. But in EJB3, we use easy-to-use Java annotations to specify POJO metadata and glue the components with containers. For instance, a stateless session bean in EJB3 could be as follows. The @PostConstruct annotated method is a POJO lifecycle method and it is invoked right after the bean is created.
Example 1.1. A POJO Session Bean Component in EJB3
@Stateless
public class MyBean implements MyInterface {
public void myBusinessMethod () {
// ... ...
}
@PostConstruct
public void myInitMethod () {
// Invoked right after the bean is created
// ... ...
}
}
Annotated lifecycle methods
The annotated lifecycle methods can have any method name. The container uses the annotations to determine which methods are lifecycle methods.
Another important scenario is to use managed POJOs for data models. For instance, in the following example, the EJB3 container maps the Product class to a relational database table of the same name. The container figures out the structure of the table based on the class's JavaBean properties (i.e., the getter and setter methods). So, the table has an ProductId column and a ProductName column. All operations on Product instances are automatically translated to SQL statements by the container and persisted to the relational database. You can read more about EJB3 POJO entity beans in Chapter 4, Develop a Data Model and Chapter 10, Complex ORM.
Example 1.2. A POJO Entity Bean Component in EJB3
@Entity
public class Product
implements Serializable
{
private long productId;
private String productName;
@Id
@GeneratedValue
public int getProductId () {
return productId;
}
public void setProductId (int id) {
this.productId = id;
}
public String getProductName () {
return productName;
}
public void setProductName (String name) {
this.productName = name;
}
}
In EJB3, annotations are used not only to define EJB components but also to deliver container services to POJOs. In fact, the wide use annotation is a main characteristic that differentiates EJB3 from EJB 2.1 and even some other earlier lightweight frameworks.
As we discussed earlier in this chapter, declarative services are a key concept in Java enterprise middleware, freeing developers from coding tedious cross-cutting concerns (e.g., logging, transaction and security) that are not essential to the business logic. In J2EE 1.4 and some other enterprise Java frameworks (e.g., the Spring framework), XML configuration files are used extensively to deliver services to Java objects. For instance, you can declare transactional and security properties of methods in a separate XML file. The container reads in the XML file at runtime and applies those services to the methods. However, as the container grows bigger and more complex, the complexity of the XML configuration files quickly grows out of control. In a typical J2EE 1.4 application (or Spring application), you can easily have as much "XML code" as Java code.
The biggest problem with XML configuration files is they are very repetitive. The repetition comes from the separation between the Java code and code configuration. You have to repeat the same information in both the Java code and the XML configuration file in order to connect the two. In the XML file, you have to verbosely "describe" which class and methods each setting applies to. If you make one typo, well, the application breaks with hard-to-debug errors.
To compound this problem, older frameworks do not provide sensible default configuration settings. You have to spell out everything explicitly in XML code. It makes the XML files very hard to read and extremely tedious to write by hand. Just take a look at the security configuration in J2EE 1.4 or transaction configuration in Spring, and you will immediately understand what we mean here.
The problems with external XML metadata have been refereed to as "XML hell", and it is one of the major complaints developers have against J2EE 1.4. As developers become frustrated with XML files, they invent new solutions. The open source XDoclet project allows you to define metadata in specially formatted JavaDoc comments. The XDoclet pre-processor analyzes the code and automatically generates all the correct J2EE XML files. This approach makes developer's life easier by putting code and code-related configuration metadata close together in the same file. The developer can quickly associate the two pieces of information without switching between editor windows. XDoclet has become a wildly popular project among J2EE developers.
Learning from the success of XDoclet, Sun added a new language feature known as annotations in the Java language in Java SE 5.0. Annotations embed metadata inside Java source code. There is no need to duplicate Java class and method names in an external file. Compilers can more easily check structure of annotations, and IDEs can offer and even higher level of validation. Hence, misspellings and other usage mistakes can be easily caught. Embedding metadata in Java source code is no longer the "hack" XDoclet used to be. The following listing shows a transactional method example in EJB3 annotations.
Example 1.3. Deliver Transaction Service to an EJB3 POJO via Annotations
@Stateless
public class MyBean implements MyInterface {
@TransactionAttribute(
TransactionAttributeType.REQUIRED)
public void myBusinessMethod () {
// ... database operations...
}
// ... ...
}
Configuration by Exception
EJB3 defines a set of reasonable default configuration values for each component. If you do not wish to change the default, you do not need to specify any configuration metadata at all. For instance, in an EJB3 session bean, a method's transaction property is REQUIRED by default. So, in the previous code listing, the @TransactionAttribute is not necessary. That is in sharp contrast with EJB 2.1, where all configuration options must be repetitively spelled out in XML files.
This design is more generally known as "configuration by exception". It greatly simplifies the code for most applications.
Java EE 5.0 and EJB3 specifications define standard Java annotations you can use in any Java EE application servers. That essentially makes annotations a part of the standard Java API, just like API classes and methods. In this book, we will focus heavily on the annotation API of EJB3.
The Case for XML files
While we recommend using annotations to configure your lightweight applications, there are always developers who prefer to work with XML deployment descriptors. XML configuration files do offer more flexibility by separating metadata from code and allowing you to change configuration at deployment time without re-compiling the code.
For those developers, the good news is that EJB3 does support XML deployment descriptors. In fact, all EJB3 annotations can be substituted by XML configuration elements.
As we mentioned, a core architectural design pattern in J2EE is Inversion of Control (IoC), which allows developers to write loosely coupled components. However, in J2EE 1.4, the implementation of IoC is based on "dependency lookup". For instance, if a session bean needs to obtain an instance of a database resource, the session bean needs to explicitly lookup the database by its name via a JNDI call. The following code snippet shows how to look up a container managed DataSource object under the JNDI name "defaultDS". You can then use this object to access the server's default database.
Example 1.4. Dependency Lookup before EJB3
DataSource ds;
// Boilerplate code follows ...
try {
InitialContext ctx = new InitialContext();
ds = (DataSource) ctx.lookup("DefaultDS");
} catch (Exception e) {
// Handle the exception
}
// ... use ds ...
The dependency lookup code is boilerplate code since it is not part of your business logic and it clutters your Java business classes. In addition, the dependency lookup code assumes that JNDI is running in the container. If you decide to use another service management framework (e.g., the JBoss MicroContainer and Spring Framework), you would have to change all occurrences of the lookup code. A better solution is to use the "dependency injection" pattern to "wire" container-managed objects into each other. You simply need to declare the dependencies among objects using metadata. Again, some frameworks use verbose XML files to express dependency metadata. In Java EE 5.0 and EJB3, we use the simpler Java annotations to inject dependency objects. For instance, the following code snippet shows how to obtain a database resource object and an entity bean persistence manager object (see Chapter 4, Develop a Data Model) in an EJB3 session bean.
Example 1.5. Dependency Injection in an EJB3 POJO Component
@Stateless
public class MyBean implements MyInterface {
@Resource
DataSource defaultDS;
// ... use defaultDS ...
}
The @Resource annotation tells the container to inject a value to the defaultDS variable in the EJB 3.0 session bean. The injection happens before the variable is first used. The container decides which DataSource object to inject based on the target's variable name. In this case, the DataSource under JNDI name "defaultDS" is automatically assigned to the defaultDS variable. Notice that the container can even inject values to private field variables.
Dependency injection allows for the development of simple application components that aren't tied to their environment. It eliminates the need for cumbersome JNDI lookups or homegrown service locators to interact with other parts of the application. Not only does this greatly simplify the code in normal use, but it also allows for easy testability of the application.
Even the most powerful enterprise Java containers cannot provide all the services all applications need. In a lightweight enterprise Java framework, POJOs should not only consume container services but also offer services to other POJOs in the system. This way, we can extend container services using POJOs.
In EJB3, you can use interceptors to deliver custom services to EJB3 components. The custom services can be as rich as the regular container service. They can be delivered to the components via annotations as well. In Chapter 11, Extend Container Services, we will show how to develop your own service annotations using EJB3 interceptors.
As an executive member of the Java Community Process (JCP), JBoss is committed to support standard-based technologies. Open standards promote competition and fit well with the Open Source development model JBoss excels. Hence, the lightweight application development framework in JBoss Application Server (AS) is built upon standard-based Java technologies. The key components in the JBoss lightweight framework are EJB3, JSF and JBoss Seam. Figure 1.2, “Architecture of a typical JBoss lightweight web application” shows how the architecture of a typical web application: EJB3 provides the persistence and business logic; JSF handles user interaction and renders the view through UI components; and Seam is an optional bridge between JSF and EJB3 with support for stateful components that span across a wide range of contexts, from local conversations to multi-user business processes. Under this architecture, there is no repetitive XML code, no artificial value objects, no convoluted SQL statements, and no messy HTML markups.
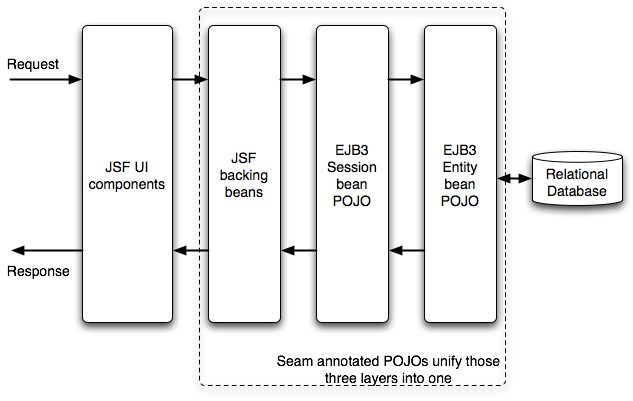
In this book, we will show how those technologies work together to enable agile development of web applications. In this section, let's first have a brief introduction to those technologies.
Install and run JBoss AS
The JBoss AS 4.0.x series supports the lightweight frameworks we cover in this book. But for the best experience, we recommend you to use JBoss AS 4.0.4 and later to run the examples in this book.
You can check out the Appendix A, Install and Deploy JBoss AS of this book for instructions on how to install and run the JBoss AS with lightweight framework support.
As we discussed, EJB3 is the central piece of lightweight technology in Java EE standards. In a JBoss lightweight web application, the business logic, including transactional data persistence, are implemented in EJB3 components. An EJB3 application primarily consists of annotated POJOs and very little XML. The business logic is fully encapsulated in reusable POJO components. EJB3 applications are easy to write and maintain. The EJB3 container provides a whole slew of proven useful services for the POJO components, and it manages the lifecycle of components to enable dependency injection.
EJB3 entity beans are used to build the data model for the application. The container automatically maps the entity beans, including their association and inheritance relationships, into relational data tables for persistence (see Chapter 4, Develop a Data Model and Chapter 10, Complex ORM for more). In JBoss AS, EJB3 entity beans are implemented on top of the widely used Open Source Hibernate framework. Hibernate is a proven and the most widely used Object-Relational Mapping (ORM) framework in Java. It can be used both inside and outside of the JBoss AS container. In fact, Hibernate support a superset of EJB3 persistence annotations. You can use those Hibernate-specific annotations (see an example in Chapter 8, Validation) to handle complex ORM scenarios not yet covered by EJB3.
EJB3 session beans provide transactional access to databases, message queues, and other resources. Session beans allow for dependency injection of container-managed resources and application components. For instance, you can inject an EntityManager component, which provides access to databases via the entity beans, into the session bean. Session beans themselves can also be injected into other application components.
Session beans can expose both remote and local interfaces to client code. Only the interfaces are exposed, leaving the rest of the application completely decoupled from the code that implements the session bean's functionality. Session beans can also have container-managed states independent of the web application's HTTP session state (see Chapter 14, Integrate JSF with EJB3 and Chapter 15, Integrate Business Processes for more).
In JBoss AS, EJB3 session beans are built upon the JBoss AOP (Aspect Oriented Programming) framework. AOP interceptors analyze the annotations on the session bean POJOs and inject the required services. Since JBoss AOP is an Open Source project, you can expand the container by adding your own annotations to deliver custom services to EJB3 session beans. In addition to the standard EJB3 container services, JBoss also provides custom annotations for session bean like components. For instance, the JBoss JMX service POJO is very similar to an EJB3 session bean but provides for access via the JMX microkernel in JBoss AS (see JBoss AS documentation for more).
EJB3 message driven beans are annotated lightweight components that act as message queue endpoints (see Chapter 9, Asynchronous Processing for more). They respond to incoming messages received by the Java Messaging Service (JMS) queue they listen to. JBoss AS creates and manages the JMS queues for the message driven beans. You can also inject other components or resources into a message driven bean.
In addition to the standard EJB3 message driven bean. The JBoss AS supports a session bean like POJO construct called message driven POJO. You can make asynchronous calls via JMS using those POJOs (see Chapter 9, Asynchronous Processing).
EJB3 POJO components handle the business logic but they do not interact with the web browsers. A complete web application requires a web framework to generate HTML pages, receive user input, and manage the navigation flow. The consensus among most web developers is that a Model-View-Controller (MVC) architecture is the best for web frameworks. In an MVC framework, the controller takes user input and decides which view to show next; The view renders the HTML page for the browser; The model encapsulates data captured from the web form and to be displayed on the web page.
There are many web frameworks available. We've chosen JavaServer Faces (JSF), the standard Java EE web framework . While JSF does have a leg up on the competition by being a standards-based technology, the decision to embrace JSF over the alternatives goes much deeper.
JSF is a well-designed and easy-to-use component-based web framework. This component-based development model aligns perfectly with the lightweight POJO approach we are promoting. The development model is clean and simple.
Shield developers from the messy HTML / JavaScript / CSS details
Enterprise Java developers have long embraced ORM solutions, which automatically generate relational database access code from the data model component in the application. JSF is the "ORM solution for the web layer". It automatically generates HTML / JavaScript / CSS code from well formed UI components.
A JSF application primarily contains two types of components -- both are easy to use and conforming to the POJO philosophy.
A JSF page is composed of XML tags. Each tag element corresponds to a UI component in JSF. As a web developer, you do not need to deal with the HTML markup or JavaScript details, as they are all generated from the JSF component tags. Since each UI component is self-contained and has well-defined behavior (i.e., it understand how to render itself and how to handle its data), JSF provides a very POJO-like experience for developing web UI.
Dynamic data on JSF pages and forms are modeled in POJOs known as JSF backing beans. The backing bean lifecycle is managed by the JSF server. For instance, a backing bean can have a session scope to track a user session. A backing bean can be dependency injected into another bean via an XML configuration file, and it can be injected into a JSF UI component via the JSF Expression Language (EL). The backing bean also provides the integration points between the web UI and the EJB3 business components.
The componentized UI and POJO data model make it easy to support JSF in IDE tools. In fact, many Java IDEs now support drag-and-drop UI designers for JSF. The JSF component model also allows third party vendors to develop and sell reusable UI component libraries. Those component libraries make it easy for server-side developers to take advantage of the latest browser technology without the need to mess with JavaScripts and such. For instance, in Chapter 13, Rich UI and AJAX, we will discuss how to use rich UI and AJAX component libraries in JSF.
The JSF request model is powerful and easy to extend. Technologies like Facelets and Seam have been developed on top of JSF, providing even richer development environments. While competing frameworks all have nice features, JSF seems to be the easiest to extend. We expect even more innovative extensions in the near future, clearly making JSF the framework of choice for most EE projects.
Of course, JSF isn't without its drawbacks. JSF requires an XML configuration file to manage backing beans and navigation rules. As we will also soon see, the integration between JSF backing beans and EJB3 beans is not entirely smooth. In addition, JSF usage from JSPs can get tricky at times. However, these problems are not entirely unique to JSF. Other frameworks exhibit similar problems. The good news is that the JSF model is advanced enough that solutions to all of the issues have been developed. We will look at those solutions in Chapter 13, Rich UI and AJAX and Chapter 14, Integrate JSF with EJB3.
In JBoss AS, the JSF implementation is provided by the Apache MyFaces project. The MyFaces project not only provides a standard-compliant JSF implementation, but also add-on UI components and data validators (see Chapter 13, Rich UI and AJAX). In addition, the Oracle ADF Faces, recently donated to Apache as an Open Source project, provides a large set of high performance rich UI components for free.
As we mentioned in the previous section, one JSF shortcoming is that its integration with EJB3 is not entirely smooth. On the programming model level, JSF components are configured over XML while EJB3 components are configured with annotation. On the integration level, the JSF backing beans and EJB3 components must have different Java classes, and that could force unnecessary tiers in the application.
The JBoss Seam framework aims to resolve those inconsistencies and support the EJB3-style programming model in the entire application. Under Seam, EJB3 beans can be JSF backing beans themselves. All components in JSF and EJB3 can now cross-reference each other under a unified set of annotations and Expression Language (EL). XML files are only used for defining processes, such as page flows or long running business processes.
Seam is beyond a simple bridge between JSF and EJB3. It makes innovative use of EJB3 stateful components and is inherently a stateful framework. It manages application states from short conversations (lasting several minutes) to long running business processes (lasting months) across several users. Because state management is built into the most basic Seam components, Seam applications can support isolated application states in each browser window (or tab). The browser "back" button also works robustly in Seam.
While Seam enables JSF and EJB3 standards to work better together, Seam itself is not yet a Java standard. At the time of this writing, the JCP is considering adopting a Seam-like contextual component model for a future Java EE specification,. In this book, we develop most of our example applications in plain JSF and EJB3 without Seam. In Chapter 14, Integrate JSF with EJB3 and Chapter 15, Integrate Business Processes, we will introduce Seam and show you how Seam further simplifies web application development.
Lightweight Java application frameworks have seen great success in the past several years to address the shortcomings of J2EE 1.4. With the new Java EE 5.0 and EJB3 specifications, the standard Java application servers support lightweight development models, without compromising the power and flexibility of J2EE. As a leader in both the Java standard organization and the lightweight framework movement, the JBoss Application Server is your best choice in developing your next generation enterprise Java applications. In the rest of this book, we will use several sample applications to show you how to develop production-ready applications using EJB3, JSF, and Seam.