|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||
See:
Description
| Interface Summary | |
|---|---|
| Activity | piece of Java code that is to be included in a process as the runtime node behaviour or as a hidden listener to process events. |
| Comment | a free text comment that can be made to an Execution
or a task. |
| CompositeElement | node container base class for ProcessDefinition and Node. |
| Condition | user code that reflects a runtime calculation of a boolean value. |
| Event | a event that will be fired at runtime by ProcessElements
and on which Activitys can be added as listeners. |
| ExceptionHandler | can handle exceptions that occur in user code like Activitys
and ExternalActivitys. |
| Execution | a runtime path of execution. |
| ExternalActivity | extends Activity for handling external triggers after a wait state. |
| Node | a node in a ProcessDefinition graph. |
| ObservableElement | a super class for process elements that have events. |
| ProcessDefinition | a graph (or tree) structure that can be executed. |
| ProcessElement | common base interface for all process definition objects that can have exception handlers and properties. |
| Transition | a transition in a ProcessDefinition graph. |
| VariableDefinition | declaration of a variable. |
| VariableScope | a scope of variables associated to an execution. |
| Class Summary | |
|---|---|
| ProcessFactory | factory for process definitions. |
| SignalDefinition | describes the signature of an external trigger. |
| SignalDefinition.SetBuilder | |
process definitions, executions and the delegation interfaces for associating programming logic to the process.
The article The Process Virtual Machine describes the concepts and background of this implementation.
In essence, the process virtual machine is a framework for implementing advanced state machines. It's done in such a way that it's easy to build workflow, BPM, orchestration and other graph based execution langauges on top of it. Examples of languages that have been built on top of this library:
Even while the nature of these languages is already very diverse, these are all examples of general purpose workflow languages. The real power of the Process Virtual Machine is that it's very easy to build Domain Specific Languages (DSL) with it. For instance, it's very easy to build a very simple (and dedicated) workflow language to specify approvals related to documents in a document management system.
The data structures of the Process Virtual Machine can be categorized into 3 distinct parts :
These three parts have different characteristics for persistence and caching. Process definition information is typically static. Execution is dynamic and has references to process definition information. The history logs are inserted and never updated and can only have references to process definition information, not to execution information as that may be volatile.
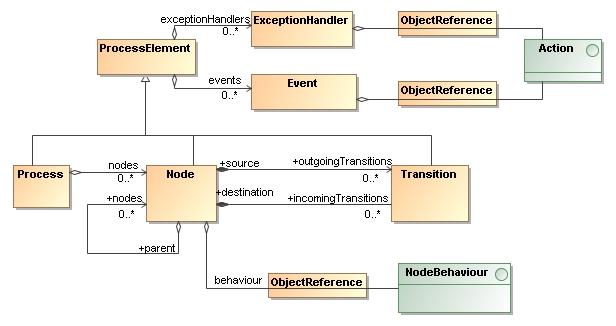
A ProcessDefinition is a graph based
description of a state machine. It's made up of
Nodes and Transitions. These relate
to the graphical representation and form the structure of the process.
The nodes form the steps in the process and they are sometimes referred to as
activities. Nodes can be executed by the system that is executing the process,
in that case, they are also known as automatic activities. Nodes can also
represent things that need to be done by another system or a person. That
implies that such a node will be a wait state for the system that is executing
the process.
A ProcessDefinition can be considered static during
execution. That is analogue to java classes and objects. The process virtual
machine could also be used for process definitions that change during execution
but we'll leave that up to the advanced user to keep this explaination focussed.
So in this introduction, process definitions can be considered the static
information.
The process definition model in the process virtual machine supports
both graph based process languages and block structured languages.
With nodes and transitions graph based languages can be implemented and
with the composite nodes, block structured languages can be implemented.
Even graph structures can be combined with composite node structures.
See Node for more information on that.
The nodes and transitions form the basis of a process. But with nodes
and transitions alone, there is no runtime behaviour associated with the
process graph. That is delegated to interface Activity.
With that interface, programming logic is bound to the process structure.
A process language typically specifies a number of reusable process constructs.
In the Process Virtual Machine, this translates to a number of reusable and
configurable Activity implementations. The configurations
of process constructs are represented in the member fields of the
Activity.
So here is an overview of the process definition classes.
The process structure of nodes, transitions and composite nodes can be decorated with event listeners. Another way of describing event listeners is that it's a mechanism to include hidden pieces of Java code into the execution of a process. So event listeners (unlike nodes and transitions) are not to be represented graphically. This is one mechanism to keep the graphical representation decoupled from the actual implementation details. It ensures that a developer does not have to mess with a business analysts' diagram to make it executable.
Activitys and
Conditions are special parts of the process definition
model. That is because they are the delegation interfaces that refer to
programming logic associated to the process structure. The execution knows
how to interpret the process definition structures, but delegates the
node behaviour and event listeners to Activitys
and the conditions to Conditions.
The delegation interfaces have two major implications.
Activitys. The process constructs
can now be coded in java itself. So process languages can be built
on top of the Process Virtual Machine as a set of Activity
implementations.
Events are points in the process definition to which event listeners can be subscribed
in the form of Activitys. Events are identified by the combination
of a process element and an event name. For
example the node-enter
By default events will propagate over the parent
hierarchy. This means that you can for example add a
transition-take event to a process definition
to be notified of all transitions that are being taken in a process definition. Inside of the
action the execution will provide access to the Execution.getEventSource(),
which will point to the original process element on which
the event was fired.
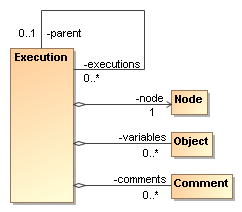
An Execution represents the
runtime state for one execution of a process. The most important part of
the state is the pointer to the
current node.
Also the process variables
and the comments are part of the
runtime state of an execution.
The execution that is created by ProcessDefinition.startExecution()
is the main path of execution. This can be considered the process instance. In case
this process execution will get concurrent paths of executions, the
parent-child
relation can be used. Execution has a set of child executions.
Variables can be associated to an execution. Variables are like a Map: the keys are java.lang.String's and values are any Java object. In case you want to persist your execution, you have to be aware that not all Java types are supported out of the box. For more information about the variable typing system and how to tweak the default configuration, see package org.jbpm.pvm.type.
Variables are stored in variable scopes. Typically those are defined in the process definition and as a user of variables, you don't have to be aware of that. Each execution has a list of variable scopes. The most inner scope is located at the beginning of the list and the most outer scope is at the end of the variable scope list. This gives the typical variable scoping rules as in any programming language.
In an execution, variables can be created dynamically without a declaration. In that case, the name and object will be used to determine the type. For configuration of the dynamic type resolution, see package org.jbpm.pvm.type.
The creation and destruction of variable scopes is typically done by the process language and it's baked into the process definition information. But you can manipulate the variable scopes programmatically as well.
But Execution.getVariableScopeIterator() gives access to the
concatenated stacks of variable scopes over the parent execution chain.
The scopes offered in the iterator are ordered from inner to outer. The interfaces
are structured in such a way that process languages can combine variable scopes in
other persistable entities. For example, a bpel scope object could include runtime
correlation sets, active exception handler pointers and variables.
The history of an execution is a kind of audit trail that captures all the detailed information about when and how an execution changed it's state. It includes external triggers, state changes, process variable updates and so on. Potentially, this information could be sufficient to replay or to roll back an execution. Of course, this generating and storing history information should be optional. From the raw logging information, business intelligence information can be derived. This is basically the same information, but structured differently resulting in an easy-to-query relational database schema.
An asynchronous continuation (aka safepoint) means that logically, the process keeps executing, but the current transaction must be committed and a new transaction must be started automatically in which the execution is resumed. This implies that the process execution will continue in a new thread.
A process is executed in atomic steps called AtomicOperations.
An atomic operation is an uninterruptable piece of progress in the
process execution.
By default process execution is synchonous, which means that method
Execution.signal() will block until the process
arrives in a wait state. The thread of the client will be used to
interprete/execute the process.
Potentially, the calculation time needed to execute the process till that next wait state might be too long. For example, when automatic activities are long calculations like in pdf generation.
Before and after an atomic operation, process execution can be stopped,
which means that the blocking method Execution.signal()
will return and the process can potentially be saved. Before the
execution returned, it will also have sent an asynchronous message with the
MessageSession. The destination of the message is
responsible for resuming process execution by executing the next atomic
operation.
An execution can stop running in 3 specific situations:
The latter two are asynchronous continuations. The asynchronous
continuation implementation depends on a
jbpm-defined asynchronous message
session. An implementation of that interface must be available in the
Environment. This library contains implementations that
bind the jbpm message session to JMS and in-memory blocking queue.
Jobs are the messages that will be sent to the job executor component over the asynchronous messaging service.
During an asynchronous continuation, the execution is
locked so that
potentially other competing external triggers do not interfere with the
execution. Locking does not include a security aspect here. It's just
a precautionary measure to prevent that other signals are given to the
execution, which is conceptually still running.
All jBPM exceptions are runtime exceptions. The base class of exceptions
is PvmException. Exceptions are not handled by the Process Virtual Machine
library itself. So exceptions that are thrown by user code in delegation
classes like Activity
or Condition will come out of the method that was invoked
by the client. Similarly for PvmExceptions that are thrown by jBPM
because the process couldn't be interpreted by the execution for some reason.
Exceptions that come out of execution methods are non recoverable. When an exception occurs in an execution, that execution should be discarded. If that exception occured in the context of a transaction, that transaction should be rolled back.
Exception handlers are part of the process definition and allow for java exceptions to be handled that occur during process execution. These exception handlers have nothing to do with business exceptions. Business level exceptions in business processes should be modelled at the process language level. Business exceptions is mostly a modelling aspect and it doesn't require special execution semantics.
A list of exception handlers can be associated with every process element like a node, a transition or a process. When an exception occurs in one of the delegation classes, a matching exception handler is searched for starting from the current process element up the parent hierarchy. If such an exception handler is found, it is invoked and given a chance to handle the exception. If the exception handler returns normally without an exception, then the exception is considered handled and the execution proceeds. If the exception handler itself throws an exception, the search for an appropriate exception handler continues until the top level process element, which is the process definition.
So exception handlers are only able to eat exceptions that come out of delegation classes. So either the exception is handled and the execution proceeds from the point where the exception was thrown. Or the exception is not handled and then it is thrown to the original client. Exception handlers can not change the control flow of the execution.
All methods of process definition objects that are called during execution of a process are supposed to be thread safe. Process execution objects don't have to be thread safe. There will always be 1 object per thread.
Building the process definition object graph is usually done single threaded. Also executions typically have their own set of objects per thread as this is a core paradigm in current ORM solutions like hibernate and JPA.
Every process language might have a number of extensions that are related to the execution. E.g. jPDL has Tasks, Swimlanes, Comments and possibly some node state informations. BPEL has partnerlinks and correlation sets.
See also Execution.getExtension(Class).
Since every process language needs variables, they are moved to the execution itself. (is this a good choice ?)
|
|||||||||
| PREV PACKAGE NEXT PACKAGE | FRAMES NO FRAMES | ||||||||