An important aspect of business processes is human task management. While some of the work performed in a process can be executed automatically, some tasks need to be executed by human actors.
jBPM supports a special human task node inside processes for modeling this interaction with human users. This human task node allows process designers to define the properties related to the task that the human actor needs to execute, like for example the type of task, the actor(s), or the data associated with the task.
jBPM also includes a so-called human task service, a back-end service that manages the life cycle of these tasks at runtime. The jBPM implementation is based on the WS-HumanTask specification. Note however that this implementation is fully pluggable, meaning that users can integrate their own human task solution if necessary.
In order to have human actors participate in your processes, you first need to (1) include human task nodes inside your process to model the interaction with human actors, (2) integrate a task management component (like for example the WS-HumanTask based implementation provided by jBPM) and (3) have end users interact with a human task client to request their task list and claim and complete the tasks assigned to them. Each of these three elements will be discussed in more detail in the next sections.

jBPM supports the use of human tasks inside processes using a special user task node (as shown in the figure above). A user task node represents an atomic task that needs to be executed by a human actor.
[Although jBPM has a special user task node for including human tasks inside a process, human tasks are considered the same as any other kind of external service that needs to be invoked and are therefore simply implemented as a domain-specific service. See the chapter on domain-specific processes to learn more about this.]
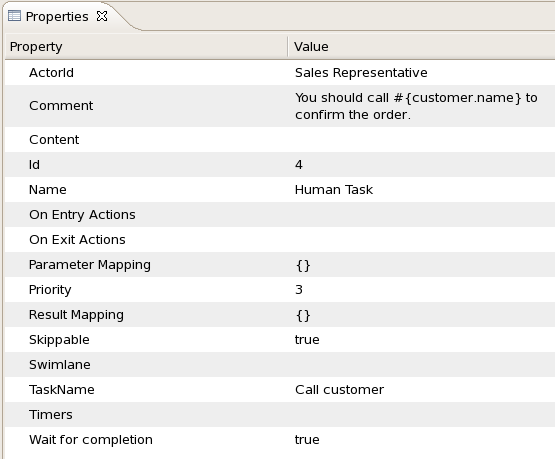
A user task node contains the following properties:
Id: The id of the node (which is unique within one node container).
Name: The display name of the node.
TaskName: The name of the human task.
Priority: An integer indicating the priority of the human task.
Comment: A comment associated with the human task.
ActorId: The actor id that is responsible for executing the human task. A list of actor id's can be specified using a comma (',') as separator.
GroupId: The group id that is responsible for executing the human task. A list of group id's can be specified using a comma (',') as separator.
Skippable: Specifies whether the human task can be skipped, i.e., whether the actor may decide not to execute the task.
Content: The data associated with this task.
Swimlane: The swimlane this human task node is part of. Swimlanes make it easy to assign multiple human tasks to the same actor. See the human tasks chapter for more detail on how to use swimlanes.
On entry and on exit actions: Action scripts that are executed upon entry and exit of this node, respectively.
Parameter mapping: Allows copying the value of process variables to parameters of the human task. Upon creation of the human tasks, the values will be copied.
Result mapping: Allows copying the value of result parameters of the human task to a process variable. Upon completion of the human task, the values will be copied. A human task has a result variable "Result" that contains the data returned by the human actor. The variable "ActorId" contains the id of the actor that actually executed the task.
You can edit these variables in the properties view (see below) when selecting the user task node, or the most important properties can also be edited by double-clicking the user task node, after which a custom user task node editor is opened, as shown below as well.
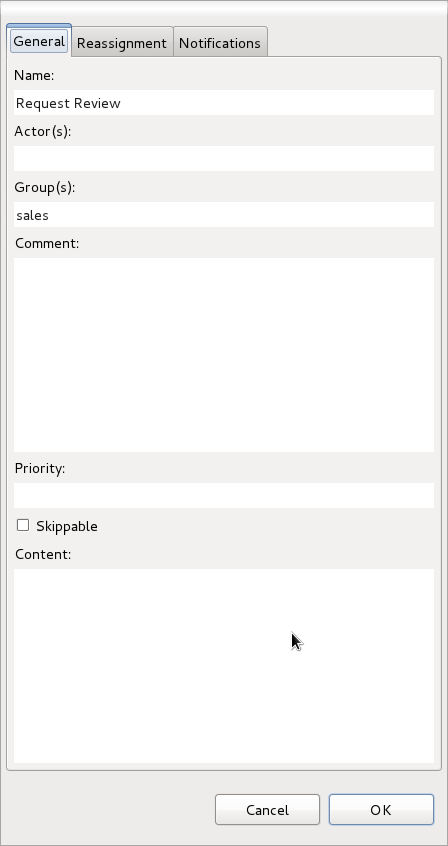
In many cases, the parameters of a user task (like for example the task name, actorId, or priority) can be defined when creating the process. You simply fill in the value of these properties in the property editor. It is however likely that some of the properties of the human task are dependent on some data related to the process instance this task is being requested in. For example, if a business process is used to model how to handle incoming sales requests, tasks that are assigned to a sales representative could include information related to that specific sales request, like its unique id, the name of the customer that requested it, etc. You can make your human task properties dynamic in two ways:
- #{expression}: Task parameters of type String can use #{expression} to embed the value of the given expression in the String. For example, the comment related to a task might be "Please review this request from user #{user}", where user is a variable in the process. At runtime, #{user} will be replaced by the actual user name for that specific process instance. The value of #{expression} will be resolved when creating human task and the #{...} will be replaced by the toString() value of the value it resolves to. The expression could simply be the name of a variable (in which case it will be resolved to the value of the variable), but more advanced MVEL expressions are possible as well, like for example #{person.name.firstname}. Note that this approach can only be used for String parameters. Other parameters should use parameter mapping to map a value to that parameter.
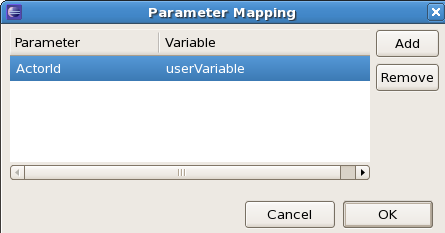
- Parameter mapping: You can map the value of a process variable (or a value derived from a variable) to a task parameter. For example, if you need to assign a task to a user whose id is a variable in your process, you can do so by mapping that variable to the parameter ActorId, as shown in the following screenshot. [Note that, for parameters of type String, this would be identical to specifying the ActorId using #{userVariable}, so it would probably be easier to use #{expression} in this case, but parameter mapping also allow you to assign a value to properties that are not of type String.]
Tasks can be assigned to one specific user. In that case, the task will show up on the task list of that specific user only. If a task is assigned to more than one user, any of those users can claim and execute this task.
Tasks can also be assigned to one or more groups. This means that any user that is part of the group can claim and execute the task. For more information on how user and group management is handled in the default human task service, check out the user and group assignment.
There are number of situations that can raise a need for escalation of a task, for instance - user assigned to a task can be on vacation or too busy with other work. In such cases task should be automatically reassigned to another actor or group. Escalation can be defined for tasks that are in following statuses:
- not started (READY or RESERVED)
- not completed (IN_PROGRESS)
Whenever an escalation is reached users/groups defined in it will be assigned to the task as potential owners, replacing those that were previously set. If actual owner was already assigned it will be reset and task will be put in READY state.
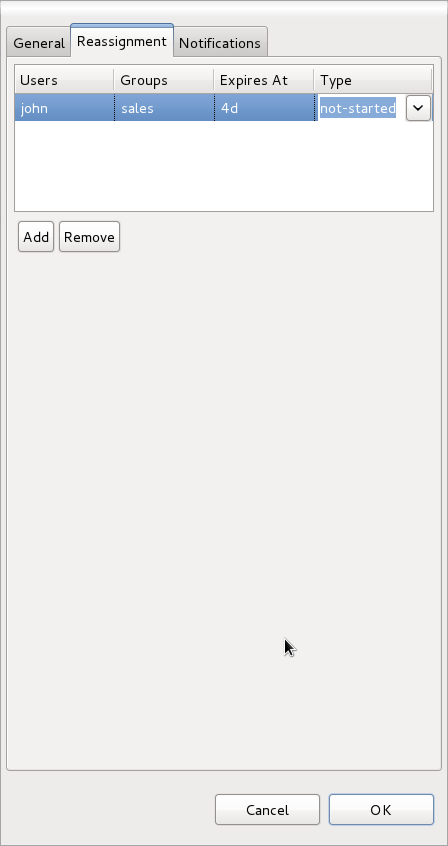
Following is a list of attributes that can be specified:
Users: comma spearated list of user ids that should be assigned to the task on escalation. Acceptable are String values and expressions #{user-id}
Groups: comma spearated list of group ids that should be assigned to the task on escalation. Acceptable are String values and expressions #{group-id}
Expires At: time definition about when escalation should take place. It should be defined as time defintion (2m, 4h, 6d, etc.), in same way as for timers. Acceptable are String values and expressions #{expiresAt}
Type: identifies type of task state on which escalation should take place (not-started | not-completed)
In addition to escalation, email notifications can be sent out as well. It is very similar to escalation in terms of definition, allows notification to be sent for tasks that are in following statuses:
- not started (READY or RESERVED)
- not completed (IN_PROGRESS)

Email notification has following properties:
Type: identifies type of task state on which escalation should take place (not-started | not-completed)
Expires At: time definition about when escalation should take place. It should be defined as time defintion (2m, 4h, 6d, etc.), in same way as for timers. Acceptable are String values and expressions #{expiresAt}
From: (Optional) user or group id that will be used as From field for email message - accepts String and expression
To Users: comman separated list of user ids that will become reciepients of the notification
To Groups: comman separated list of group ids that will become reciepients of the notification
Reply To: (Optional) user or group id that should receive replies to the notification
Subject: Subject of the notification - accepts String and expression
Body: Body of the notification - accepts String and expression
Notification can reference process variables by #{processVariable} and task variables ${taskVariable}. Main difference between those two is that process variables will be resolved at task creation time and task variables will be resolved at notification time. There are several task variables (besides regular ones) that can be used while working with notifications:
taskId: internal id of a task instance
processInstanceId: internal id of a process instance that the task belongs to
workItemId: internal id of a work item that created this task
processSessionId: session internal id of a runtime engine
owners: list of users/groups that are potential owners of the task
doc: map that contains regular task variables
An example that illustrates a simple notification message (its body) that shows how different variables can be accessed:
<html>
<body>
<b>${owners[0].id} you have been assigned to a task (task-id ${taskId})</b><br>
You can access it in your task
<a href="http://localhost:8080/jbpm-console/app.html#errai_ToolSet_Tasks;Group_Tasks.3">inbox</a><br/>
Important technical information that can be of use when working on it<br/>
- process instance id - ${processInstanceId}<br/>
- work item id - ${workItemId}<br/>
<hr/>
Here are some task variables available
<ul>
<li>ActorId = ${doc['ActorId']}</li>
<li>GroupId = ${doc['GroupId']}</li>
<li>Comment = ${doc['Comment']}</li>
</ul>
<hr/>
Here are all potential owners for this task
<ul>
$foreach{orgEntity : owners}
<li>Potential owner = ${orgEntity.id}</li>
$end{}
</ul>
<i>Regards from jBPM team</i>
</body>
</html>
Human tasks typically present some data related to the task that needs to be performed to the actor that is executing the task and usually also request the actor to provide some result data related to the execution of the task. Task forms are typically used to present this data to the actor and request results.
Data that needs to be displayed in a task form should be passed to the task, using parameter mapping. Parameter mapping allows you to copy the value of a process variable to a task parameter (as described above). This could for example be the customer name that needs to be displayed in the task form, the actual request, etc. To copy data to the task, simply map the variable to a task parameter. This parameter will then be accessible in the task form (as shown later, when describing how to create task forms).
For example, the following human task (as part of the humantask example in jbpm-examples) is assigned to a sales representative that needs to decide whether to accept or reject a request from a customer. Therefore, it copies the following process variables to the task as task parameters: the userId (of the customer doing the request), the description (of the request), and the date (of the request).
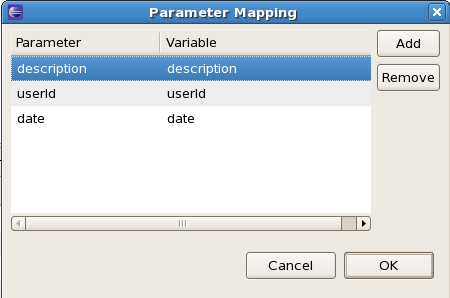
Data that needs to be returned to the process should be mapped from the task back into process variables, using result mapping. Result mapping allows you to copy the value of a task result to a process variable (as described above). This could for example be some data that the actor filled in. To copy a task result to a process variable, simply map the task result parameter to the variable in the result mapping. The value of the task result will then be copied after completion of the task so it can be used in the remainder of the process.
For example, the following human task (as part of the humantask example in jbpm-examples) is assigned to a sales representative that needs to decide whether to accept or reject a request from a customer. Therefore, it copies the following task results back to the process: the outcome (the decision that the sales representative has made regarding this request, in this case "Accept" or "Reject") and the comment (the justification why).
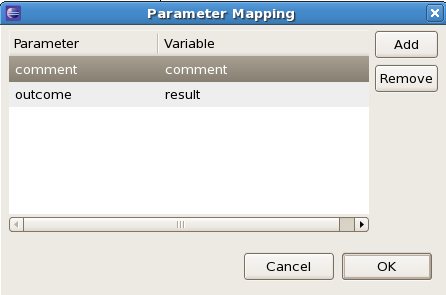
User tasks can be used in combination with swimlanes to assign multiple human tasks to the same actor. Whenever the first task in a swimlane is created, and that task has an actorId specified, that actorId will be assigned to (all other tasks of) that swimlane as well. Note that this would override the actorId of subsequent tasks in that swimlane (if specified), so only the actorId of the first human task in a swimlane will be taken into account, all others will then take the actorId as assigned in the first one.
Whenever a human task that is part of a swimlane is completed, the actorId of that swimlane is set to the actorId that executed that human task. This allows for example to assign a human task to a group of users, and to assign future tasks of that swimlame to the user that claimed the first task. This will also automatically change the assignment of tasks if at some point one of the tasks is reassigned to another user.
To add a human task to a swimlane, simply specify the name of the swimlane as the value of the "Swimlane" parameter of the user task node. A process must also define all the swimlanes that it contains. To do so, open the process properties by clicking on the background of the process and click on the "Swimlanes" property. You can add new swimlanes there.
The new BPMN2 Eclipse editor will support a visual representation of swimlanes (as horizontal lanes), so that it will be possible to define a human task as part of a swimlane simply by dropping the task in that lane on the process model.
The jbpm-examples module has some examples that show human tasks in action, like the evaluation example and the humantask example. These examples show some of the more advanced features in action, like for example group assignment, data passing in and out of human tasks, swimlanes, etc. Be sure to take a look at them for more details and a working example.
As far as the jBPM engine is concerned, human tasks are similar to any other external service that needs to be invoked and are implemented as a domain-specific service. (For more on domain-specific services, see the chapter on them here.) Because a human task is an example of such a domain-specific service, the process itself only contains a high-level, abstract description of the human task to be executed and a work item handler that is responsible for binding this (abstract) task to a specific implementation.
Users can plug in any human task service implementation, such as the one that's provided by jBPM, or they may register their own implementation. In the next paragraphs, we will describe the human task servcie implementation provided by jBPM.
The jBPM project provides a default implementation of a human task service based on the WS-HumanTask specification. If you do not need to integrate jBPM with another existing implementation of a human task service, you can use this service. The jBPM implementation manages the life cycle of the tasks (creation, claiming, completion, etc.) and stores the state of all the tasks, task lists, and other associated information. It also supports features like internationalization, calendar integration, different types of assignments, delegation, escalation and deadlines. The code for the implementation itself can be found in the jbpm-human-task module.
The jBPM task service implementation is based on the WS-HumanTask (WS-HT) specification. This specification defines (in detail) the model of the tasks, the life cycle, and many other features. It is very comprehensive and the first version can be found here.
From the perspective of a process, when a user task node is encountered during the execution, a human task is created. The process will then only leave the user task node when the associated human task has been completed or aborted.
The human task itself usually has a complete life cycle itself as well. For details beyond what is described below, please check out the WS-HumanTask specification. The following diagram is from the WS-HumanTask specification and describes the human task life cycle.
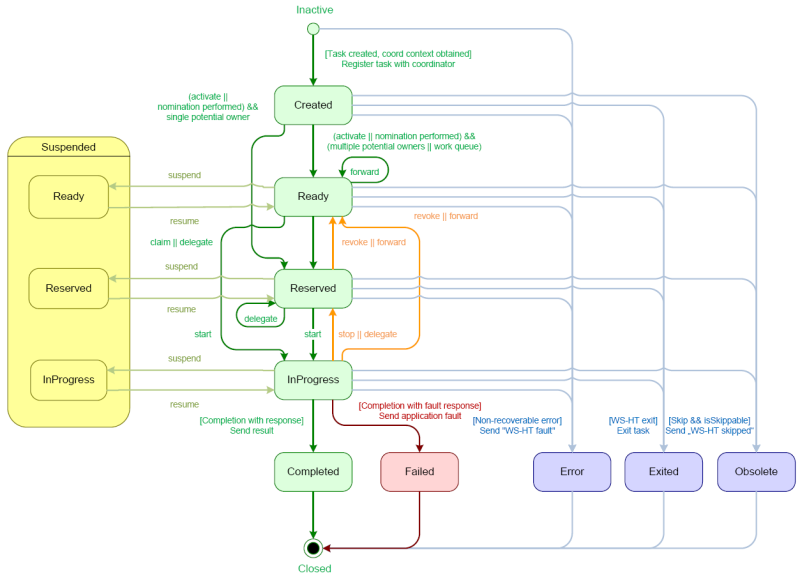
A newly created task starts in the "Created" stage. Usually, it will then automatically become "Ready", after which the task will show up on the task list of all the actors that are allowed to execute the task. The task will stay "Ready" until one of these actors claims the task, indicating that he or she will be executing it.
When a user then eventually claims the task, the status will change to "Reserved". Note that a task that only has one potential (specific) actor will automatically be assigned to that actor upon creation of the task. When the user who has claimed the task starts executing it, the task status will change from "Reserved" to "InProgress".
Lastly, once the user has performed and completed the task, the task status will change to "Completed". In this step, the user can optionally specify the result data related to the task. If the task could not be completed, the user could also indicate this by using a fault response, possibly including fault data, in which case the status would change to "Failed".
While the life cycle explained above is the normal life cycle, the specification also describes a number of other life cycle methods, including:
- Delegating or forwarding a task, so that the task is assigned to another actor
- Revoking a task, so that it is no longer claimed by one specific actor but is (re)available to all actors allowed to take it
- Temporarly suspending and resuming a task
- Stopping a task in progress
- Skipping a task (if the task has been marked as skippable), in which case the task will not be executed
Just like any other external service, the human task service can be integrated with the jBPM engine by registering a work item handler that translates the abstract work item (in this case a human task) to a specific invocation of a service (in this case, the jBPM implementation of the human task service). There are several implementations of a work item handler available that can be selected depending on following factors:
- transport used (HornetQ, Mina, JMS)
- local interaction - same transaction boundary as the engine
- mode of interaction - synchronous or asynchronous
Here is a list of all available work item handlers for human tasks:
Table 13.1. Work item handlers for human task
| Class name | Module | Mode | |
|---|---|---|---|
org.jbpm.process.workitem.wsht.LocalHTWorkItemHandler | jbpm-human-task-core | Local | |
org.jbpm.process.workitem.wsht.AsyncHornetQHTWorkItemHandler | jbpm-human-task-hornetq | Async | |
org.jbpm.process.workitem.wsht.HornetQHTWorkItemHandler | jbpm-human-task-hornetq | Sync | |
org.jbpm.process.workitem.wsht.AsyncMinaHTWorkItemHandler | jbpm-human-task-mina | Async | |
org.jbpm.process.workitem.wsht.MinaHTWorkItemHandler | jbpm-human-task-mina | Sync |
Once you select the one that meets your needs you can register this work item handler like this:
StatefulKnowledgeSession ksession = ...;
ksession.getWorkItemManager().registerWorkItemHandler("Human Task", new AsyncHornetQHTWorkItemHandler(ksession));
By default, this handler will connect to the human task service on the local machine on port 5153 via hornetq. You can easily change connection details of the human task service by either building TaskClient yourself and pass it as handler constructor argument or by setting ip address and port number after handler is created.
Note
Important to note is that when there is requirement to use multiple knowledge sessions (meaning every session will have a dedicated work item handler for human tasks) you must configure handler to react only to tasks that were initiated by that session that is attached to the handler to avoid duplicated activations.new AsyncHornetQHTWorkItemHandler(ksession, true))
The communication between the human task service and the process engine, or any task client, is message based. While the client/server transport mechanism is pluggable (allowing different implementations), the default is HornetQ. An alternative implementation using Mina (http://mina.apache.org/) is also available.
The human task service exposes a Java API for managing the life cycle of tasks. This allows clients to integrate (at a low level) with the human task service. Note that end users should probably not interact with this low-level API directly, but use one of the more user-friendly task clients (see below) instead. These clients offer a graphical user interface to request task lists, claim and complete tasks, and manage tasks in general. The task clients listed below use the Java API to internally interact with the human task service. Of course, the low-level API is also available so that developers can use it in their code to interact with the human task service directly.
A task client (class org.jbpm.task.service.TaskClient) offers the following methods (among others) for managing the life cycle of human tasks:
public void start( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void stop( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void release( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void suspend( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void resume( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void skip( long taskId, String userId, TaskOperationResponseHandler responseHandler )
public void delegate( long taskId, String userId, String targetUserId,
TaskOperationResponseHandler responseHandler )
public void complete( long taskId, String userId, ContentData outputData,
TaskOperationResponseHandler responseHandler )
If you take a look at the method signatures you will notice that almost all of these methods take the following arguments:
taskId: The id of the task that we are working with. This is usually extracted from the currently selected task in the user task list in the user interface.
userId: The id of the user that is executing the action. This is usually the id of the user that is logged in into the application.
responseHandler: Communication with the task service is asynchronous, so you should use a response handler that will be notified when the results are available.
When you invoke a message on the TaskClient, a message is created that will be sent to the server. The server then executes the operation requested in the message.
The following code sample shows how to create a task client and interact with the task service to create, start and complete a task.
TaskClient client = new TaskClient(new MinaTaskClientConnector("client 1",
new MinaTaskClientHandler(SystemEventListenerFactory.getSystemEventListener())));
client.connect("127.0.0.1", 9123);
// adding a task
BlockingAddTaskResponseHandler addTaskResponseHandler = new BlockingAddTaskResponseHandler();
Task task = ...;
client.addTask( task, null, addTaskResponseHandler );
long taskId = addTaskResponseHandler.getTaskId();
// getting tasks for user "bobba"
BlockingTaskSummaryResponseHandler taskSummaryResponseHandler =
new BlockingTaskSummaryResponseHandler();
client.getTasksAssignedAsPotentialOwner("bobba", "en-UK", taskSummaryResponseHandler);
List<TaskSummary> tasks = taskSummaryResponseHandler.getResults();
// starting a task
BlockingTaskOperationResponseHandler responseHandler =
new BlockingTaskOperationResponseHandler();
client.start( taskId, "bobba", responseHandler );
responseHandler.waitTillDone(1000);
// completing a task
responseHandler = new BlockingTaskOperationResponseHandler();
client.complete( taskId, "bobba".getId(), null, responseHandler );
responseHandler.waitTillDone(1000);
Tasks can be assigned to one specific user. In that case, the task will show up on the task list of that specific user only. If a task is assigned to more than one user, any of those users can claim and execute this task. Tasks can also be assigned to one or more groups. This means that any user that is part of the group can claim and execute the task.
The human task service needs to know about valid user and group ids (to make sure tasks are assigned to existing users and/or groups to avoid errors and tasks that end up assigned to non-existing users). User and group registration has to be done before tasks can be assigned to them. One possible registration method is to dynamically adding users and groups to the task service session:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("org.jbpm.task");
TaskService taskService = new TaskService(emf, SystemEventListenerFactory.getSystemEventListener());
TaskServiceSession taskSession = taskService.createSession();
// now register new users and groups
taskSession.addUser(new User("krisv"));
taskSession.addGroup(new Group("developers"));
The human task service itself does not maintain the relationship between users and groups. This is considered outside the scope of the human task service: in general, businesses already have existing services that manage this information (i.e. an LDAP service). The human task service does allow you to specify the list of groups that a user is part of, so that this information can also be taken into account when managing tasks.
For example, if a task is assigned to the group "sales" and the user "sales-rep-1", who is a member of "sales", wants to claim that task, then that user needs to pass the fact that he is a member of "sales" when requesting the list of tasks that he is assigned to as potential owner:
List<String> groups = new ArrayList<String>();
groups.add("sales");
taskClient.getTasksAssignedAsPotentialOwner("sales-rep", groups, "en-UK", taskSummaryHandler);
The WS-HumanTask specification also introduces the role of an administrator. An administrator can manipulate the life cycle of the task, even though he might not be assigned as a potential owner of that task. By default, jBPM registers a special user with userId "Administrator" as the administrator of each task. You should therefor make sure that you always define at least a user "Adminstrator" when registering the list of valid users at the task service.
It is often necessary to hook into existing systems and/or services (such as LDAP) where users and groups are maintained in order to perform validation without having to manually register all users and group with the task service. jBPM provides the UserGroupCallback interface which allows you to create your own implementation for user and group management:
public interface UserGroupCallback {
/**
* Resolves existence of user id.
* @param userId the user id assigned to the task
* @return true if userId exists, false otherwise.
*/
boolean existsUser(String userId);
/**
* Resolves existence of group id.
* @param groupId the group id assigned to the task
* @return true if groupId exists, false otherwise.
*/
boolean existsGroup(String groupId);
/**
* Returns list of group ids for specified user id.
* @param userId the user id assigned to the task
* @param groupIds list of group ids assigned to the task
* @param allExistingGroupIds list of all currently known group ids
* @return List of group ids.
*/
List<String> getGroupsForUser(String userId, List<String> groupIds, List<String> allExistingGroupIds);
}
If you register your own implementation of the UserGroupCallback interface, the human task service will call it whenever it needs to perform user and group validation. Here is a very simple example implementation which treats all users and groups as being valid:
public class DefaultUserGroupCallbackImpl implements UserGroupCallback {
public boolean existsUser(String userId) {
// accept all by default
return true;
}
public boolean existsGroup(String groupId) {
// accept all by default
return true;
}
public List<String> getGroupsForUser(String userId, List<String> groupIds,
List<String> allExistingGroupIds) {
if(groupIds != null) {
List<String> retList = new ArrayList<String>(groupIds);
// merge all groups
if(allExistingGroupIds != null) {
for(String grp : allExistingGroupIds) {
if(!retList.contains(grp)) {
retList.add(grp);
}
}
}
return retList;
} else {
// return empty list by default
return new ArrayList<String>();
}
}
}
You can register your own implementation of the UserGroupCallback interface in a properties file called jbpm.usergroup.callback.properties which should be available on the classpath, for example:
jbpm.usergroup.callback=org.jbpm.task.service.DefaultUserGroupCallbackImpl
or via a system property, for example
-Djbpm.usergroup.callback=org.jbpm.task.service.DefaultUserGroupCallbackImpl.
If you are using the jBPM installer, you can also modify
$jbpm-installer-dir$/task-service/resources/org/jbpm/jbpm.usergroup.callback.properties
directly to register your own callback implementation.
jBPM comes with a dedicated UserGroupCallback implementation for LDAP servers that allows task server to retrieve user and group/role information directly from LDAP. To be able to use this callback it must be configured according to specifics of LDAP server and its structure to collect proper information.
LDAP UserGroupCallback properties- ldap.bind.user : username used to connect to the LDAP server (optional if LDAP server accepts anonymous access)
- ldap.bind.pwd : password used to connect to the LDAP server(optional if LDAP server accepts anonymous access)
- ldap.user.ctx : context in LDAP that will be used when searching for user information (mandatory)
- ldap.role.ctx : context in LDAP that will be used when searching for group/role information (mandatory)
- ldap.user.roles.ctx : context in LDAP that will be used when searching for user group/role membership information (optional, if not given ldap.role.ctx will be used)
- ldap.user.filter : filter that will be used to search for user information, usually will contain substitution keys {0} to be replaced with parameters (mandatory)
- ldap.role.filter : filter that will be used to search for group/role information, usually will contain substitution keys {0} to be replaced with parameters (mandatory)
- ldap.user.roles.filter : filter that will be used to search for user group/role membership information, usually will contain substitution keys {0} to be replaced with parameters (mandatory)
- ldap.user.attr.id : attribute name of the user id in LDAP (optional, if not given 'uid' will be used)
- ldap.roles.attr.id : attribute name of the group/role id in LDAP (optional, if not given 'cn' will be used)
- ldap.user.id.dn : is user id a DN, instructs the callback to query for user DN before searching for roles (optional, default false)
- java.naming.factory.initial : initial conntext factory class name (default com.sun.jndi.ldap.LdapCtxFactory)
- java.naming.security.authentication : authentication type (none, simple, strong where simple is default one)
- java.naming.security.protocol : specifies security protocol to be used, for instance ssl
- java.naming.provider.url : LDAP url to be used default is ldap://localhost:389, or if protocol is set to ssl ldap://localhost:636
- programatically - build property object with all required attributes and register new callback
Properties properties = new Properties();
properties.setProperty(LDAPUserGroupCallbackImpl.USER_CTX, "ou=People,dc=my-domain,dc=com");
properties.setProperty(LDAPUserGroupCallbackImpl.ROLE_CTX, "ou=Roles,dc=my-domain,dc=com");
properties.setProperty(LDAPUserGroupCallbackImpl.USER_ROLES_CTX, "ou=Roles,dc=my-domain,dc=com");
properties.setProperty(LDAPUserGroupCallbackImpl.USER_FILTER, "(uid={0})");
properties.setProperty(LDAPUserGroupCallbackImpl.ROLE_FILTER, "(cn={0})");
properties.setProperty(LDAPUserGroupCallbackImpl.USER_ROLES_FILTER, "(member={0})");
UserGroupCallback ldapUserGroupCallback = new LDAPUserGroupCallbackImpl(properties);
UserGroupCallbackManager.getInstance().setCallback(ldapUserGroupCallback);
- declaratively - create property file (jbpm.usergroup.callback.properties) with all
required attributes, place it on the root of the classpath and declare LDAP callback to be registered
(see section Starting the human task server for deatils). Alternatively, location of
jbpm.usergroup.callback.properties can be specified via system property
-Djbpm.usergroup.callback.properties=FILE_LOCATION_ON_CLASSPATH
#ldap.bind.user=
#ldap.bind.pwd=
ldap.user.ctx=ou\=People,dc\=my-domain,dc\=com
ldap.role.ctx=ou\=Roles,dc\=my-domain,dc\=com
ldap.user.roles.ctx=ou\=Roles,dc\=my-domain,dc\=com
ldap.user.filter=(uid\={0})
ldap.role.filter=(cn\={0})
ldap.user.roles.filter=(member\={0})
#ldap.user.attr.id=
#ldap.roles.attr.id=
The human task service is a completely independent service that the process engine communicates with. We therefore recommend that you start it as a separate service as well. The jBPM installer contains a command to start the task server (in this case using Mina as transport protocol), or you can use the following code fragment:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("org.jbpm.task");
TaskService taskService = new TaskService(emf, SystemEventListenerFactory.getSystemEventListener());
MinaTaskServer server = new MinaTaskServer( taskService );
Thread thread = new Thread( server );
thread.start();
The task management component uses the Java Persistence API (JPA) to store all task information in a persistent manner. To configure the persistence, you need to modify the persistence.xml configuration file accordingly. We refer to the JPA documentation on how to do that. The following fragment shows for example how to use the task management component with hibernate and an in-memory H2 database:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<persistence
version="1.0"
xsi:schemaLocation=
"http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd
http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_1_0.xsd"
xmlns:orm="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="org.jbpm.task">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>org.jbpm.task.Attachment</class>
<class>org.jbpm.task.Content</class>
<class>org.jbpm.task.BooleanExpression</class>
<class>org.jbpm.task.Comment</class>
<class>org.jbpm.task.Deadline</class>
<class>org.jbpm.task.Comment</class>
<class>org.jbpm.task.Deadline</class>
<class>org.jbpm.task.Delegation</class>
<class>org.jbpm.task.Escalation</class>
<class>org.jbpm.task.Group</class>
<class>org.jbpm.task.I18NText</class>
<class>org.jbpm.task.Notification</class>
<class>org.jbpm.task.EmailNotification</class>
<class>org.jbpm.task.EmailNotificationHeader</class>
<class>org.jbpm.task.PeopleAssignments</class>
<class>org.jbpm.task.Reassignment</class>
<class>org.jbpm.task.Status</class>
<class>org.jbpm.task.Task</class>
<class>org.jbpm.task.TaskData</class>
<class>org.jbpm.task.SubTasksStrategy</class>
<class>org.jbpm.task.OnParentAbortAllSubTasksEndStrategy</class>
<class>org.jbpm.task.OnAllSubTasksEndParentEndStrategy</class>
<class>org.jbpm.task.User</class>
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<property name="hibernate.connection.driver_class" value="org.h2.Driver"/>
<property name="hibernate.connection.url" value="jdbc:h2:mem:mydb" />
<property name="hibernate.connection.username" value="sa"/>
<property name="hibernate.connection.password" value="sasa"/>
<property name="hibernate.connection.autocommit" value="false" />
<property name="hibernate.max_fetch_depth" value="3"/>
<property name="hibernate.hbm2ddl.auto" value="create" />
<property name="hibernate.show_sql" value="true" />
</properties>
</persistence-unit>
</persistence>
The first time you start the task management component, you need to make sure that all the necessary users and groups are added to the database. Our implementation requires all users and groups to be predefined before trying to assign a task to that user or group. So you need to make sure you add the necessary users and group to the database using the taskSession.addUser(user) and taskSession.addGroup(group) methods. Note that you at least need an "Administrator" user as all tasks are automatically assigned to this user as the administrator role.
The jbpm-human-task module contains a org.jbpm.task.RunTaskService class in the src/test/java source folder that can be used to start a task server. It automatically adds users and groups as defined in LoadUsers.mvel and LoadGroups.mvel configuration files.
The jBPM installer automatically starts a human task service (using an in-memory H2 database) as a separate Java application. This task service is defined in the task-service directory in the jbpm-installer folder. You can register new users and task by modifying the LoadUsers.mvel and LoadGroups.mvel scripts in the resources directory.
To allow Task Server to perform escalations and notification a bit of configuration is required. Most of the configuration is for notification support as it relies on external system (mail server) but as they are handled by EscalatedDeadlineHandler implementation so configuration apply to both.
// configure email service
Properties emailProperties = new Properties();
emailProperties.setProperty("from", "jbpm@domain.com");
emailProperties.setProperty("replyTo", "jbpm@domain.com");
emailProperties.setProperty("mail.smtp.host", "localhost");
emailProperties.setProperty("mail.smtp.port", "2345");
// configure default UserInfo
Properties userInfoProperties = new Properties();
// : separated values for each org entity email:locale:display-name
userInfoProperties.setProperty("john", "john@domain.com:en-UK:John");
userInfoProperties.setProperty("mike", "mike@domain.com:en-UK:Mike");
userInfoProperties.setProperty("Administrator", "admin@domain.com:en-UK:Admin");
// build escalation handler
DefaultEscalatedDeadlineHandler handler = new DefaultEscalatedDeadlineHandler(emailProperties);
// set user info on the escalation handler
handler.setUserInfo(new DefaultUserInfo(userInfoProperties));
EntityManagerFactory emf = Persistence.createEntityManagerFactory("org.jbpm.task");
// when building TaskService provide escalation handler as argument
TaskService taskService = new TaskService(emf, SystemEventListenerFactory.getSystemEventListener(), handler);
MinaTaskServer server = new MinaTaskServer( taskService );
Thread thread = new Thread( server );
thread.start();
Note that default implementation of UserInfo is just for demo purposes to have a fully operational task server. Custom user info classes can be provided that implement following interface:
public interface UserInfo {
String getDisplayName(OrganizationalEntity entity);
Iterator<OrganizationalEntity> getMembersForGroup(Group group);
boolean hasEmail(Group group);
String getEmailForEntity(OrganizationalEntity entity);
String getLanguageForEntity(OrganizationalEntity entity);
}
If you are using the jBPM installer, just drop your property files into
$jbpm-installer-dir$/task-service/resources/org/jbpm/, make sure that they are named email.properties
and userinfo.properties.
More production alike configuration would be to use LDAP server as user information repository and to achieve that a dedicated UserInfo implementation is shipped with jBPM - LDAPUserInfoImpl. This is especially useful when configuring task server to use LDAP based user group callback, with this complete user/group information are externalized to LDAP server.
LDAP UserGroupCallback properties- ldap.bind.user : username used to connect to the LDAP server (optional if LDAP server accepts anonymous access)
- ldap.bind.pwd : password used to connect to the LDAP server(optional if LDAP server accepts anonymous access)
- ldap.user.ctx : context in LDAP that will be used when searching for user information (mandatory)
- ldap.role.ctx : context in LDAP that will be used when searching for group/role information (mandatory)
- ldap.user.filter : filter that will be used to search for user information, usually will contain substitution keys {0} to be replaced with parameters (mandatory)
- ldap.role.filter : filter that will be used to search for group/role information, usually will contain substitution keys {0} to be replaced with parameters (mandatory)
- ldap.role.members.filter : filter that will be used to search for user group/role membership information, usually will contain substitution keys {0} to be replaced with parameters (optional default same as ldap.role.filter)
- ldap.email.attr.id : attribute id that contains email address in LDAP (default mail)
- ldap.name.attr.id : attribute id that contians display name in LDAP (default displayName)
- ldap.lang.attr.id : attribute id that contians language information (default locale)
- ldap.member.attr.id : attribute id on group/role object in LDAP that contains members (default member)
- ldap.user.attr.id : attribute id that contains user id in LDAP server (default uid)
- ldap.role.attr.id : attribute id that contains group/role id in LDAP server (default cn)
- ldap.entity.id.dn : instructs if the organizational entity is (or can be) DN, especially important when members of a group will be returned as DN instead of user ids (default false)
- java.naming.factory.initial : initial conntext factory class name (default com.sun.jndi.ldap.LdapCtxFactory)
- java.naming.security.authentication : authentication type (none, simple, strong where simple is default one)
- java.naming.security.protocol : specifies security protocol to be used, for instance ssl
- java.naming.provider.url : LDAP url to be used default is ldap://localhost:389, or if protocol is set to ssl ldap://localhost:636
- programatically - build property object with all required attributes and register
new user info on escalation handler
Properties properties = new Properties();
properties.setProperty(LDAPUserInfoImpl.USER_CTX, "ou=People,dc=jbpm,dc=org");
properties.setProperty(LDAPUserInfoImpl.ROLE_CTX, "ou=Roles,dc=jbpm,dc=org");
properties.setProperty(LDAPUserInfoImpl.USER_FILTER, "(uid={0})");
properties.setProperty(LDAPUserInfoImpl.ROLE_FILTER, "(cn={0})");
properties.setProperty(LDAPUserInfoImpl.IS_ENTITY_ID_DN, "true");
UserInfo ldapUserInfo = new LDAPUserInfoImpl(properties);
DefaultEscalatedDeadlineHandler handler = new DefaultEscalatedDeadlineHandler(emailProperties);
handler.setUserInfo(ldapUserInfo);
- declaratively - create property file (jbpm.user.info.properties) with all
required attributes, place it on the root of the classpath and declare LDAP user info implementation
to be registered (see section Starting the human task server for deatils). Alternatively, location of
jbpm.user.info.properties can be specified via system property
-Djbpm.user.info.properties=FILE_LOCATION_ON_CLASSPATH
#ldap.bind.user=
#ldap.bind.pwd=
ldap.user.ctx=ou\=People,dc\=my-domain,dc\=com
ldap.role.ctx=ou\=Roles,dc\=my-domain,dc\=com
ldap.user.filter=(uid\={0})
ldap.role.filter=(cn\={0})
#ldap.role.members.filter=
#ldap.email.attr.id
#ldap.name.attr.id
#ldap.lang.attr.id
#ldap.member.attr.id
#ldap.user.attr.id
#ldap.role.attr.id
ldap.entity.id.dn=true
Human task service can be started as web application to simplify deployment. As part of application configuration user can select number of settings to be applied on startup. Configuration is done via web.xml of jbpm-human-task-war application by setting init parameters of the HumanTaskServiceServlet.Following is a complete list of supported parameters and their meaning:
General settings
- task.persistence.unit : name of persistence unit that will be used to build EntityManagerFactory (default org.jbpm.task)
- user.group.callback.class : implementation of UserGroupCallback interface to be used to resolve users and groups (default DefaultUserGroupCallbackImpl)
- escalated.deadline.handler.class : implementation of EscalatedDeadlineHandler interface to be used to hadnle escalations and notifications (default DefaultEscalatedDeadlineHandler)
- user.info.class : implementation of UserInfo interface to be used to resolve user/group information such as email address, prefered language
- load.users : allows to specify location of a file that will be used to initially populate task server db with users. Accepts two types of files: MVEL and properties; must be suffixed with .mvel or .properties. Location of the file can be either on classpath (with prefix classpath:) or valid URL. NOTE: that with custom users files Administrator user must always be present
- load.groups : allows to specify location of a file that will be used to initially populate task server db with groups. Accepts two types of files: MVEL and properties;file must be suffixed with .mvel or .properties. Location of the file can be either on classpath (with prefix classpath:) or valid URL.
Transport settings
- active.config : main parameter that controls what transport is configured for Task Server, by default set to HornetQ and accepts Mina, HornetQ, JMS
Apache Mina
- mina.host : host/ip address used to bind Apache Mina server (localhost)
- mina.port : port used to bind Apache Mina server (default 9123)
HornetQ
- hornetq.host : host/ip address used to bind HornetQ server (default localhost)
- hornetq.port : port used to bind HornetQ server (default 5153)
JMS
- JMSTaskServer.connectionFactory : JNDI name of QueueConnectionFactory to look up (no default)
- JMSTaskServer.transacted : boolean flag that indicates if jms session will be transacted or not (no default)
- JMSTaskServer.acknowledgeMode : acknowledgment mode (default DUPS_OK_ACKNOWLEDGE)
- JMSTaskServer.queueName : name of JMS queue (no default)
- JMSTaskServer.responseQueueName : name of JMS response queue (no default)
The Drools IDE contains a org.drools.eclipse.task plugin that allows you to test and/or debug processes using human tasks. In contains a Human Task View that can connect to a running task management component, request the relevant tasks for a particular user (i.e. the tasks where the user is either a potential owner or the tasks that the user already claimed and is executing). The life cycle of these tasks can then be executed, i.e. claiming or releasing a task, starting or stopping the execution of a task, completing a task, etc. A screenshot of this Human Task View is shown below. You can configure which task management component to connect to in the Drools Task preference page (select Window -> Preferences and select Drools Task). Here you can specify the url and port (default = 127.0.0.1:9123).

Notice that this task client only supports a (small) sub-set of the features provided the human task service. But in general this is sufficient to do some initial testing and debugging or demoing inside the Eclipse IDE.
The folowing entity relationship diagram (ERD) shows the persitent entities used by the Human Task service. (Clicking on the image below will take you to an enlarged view of the image.)
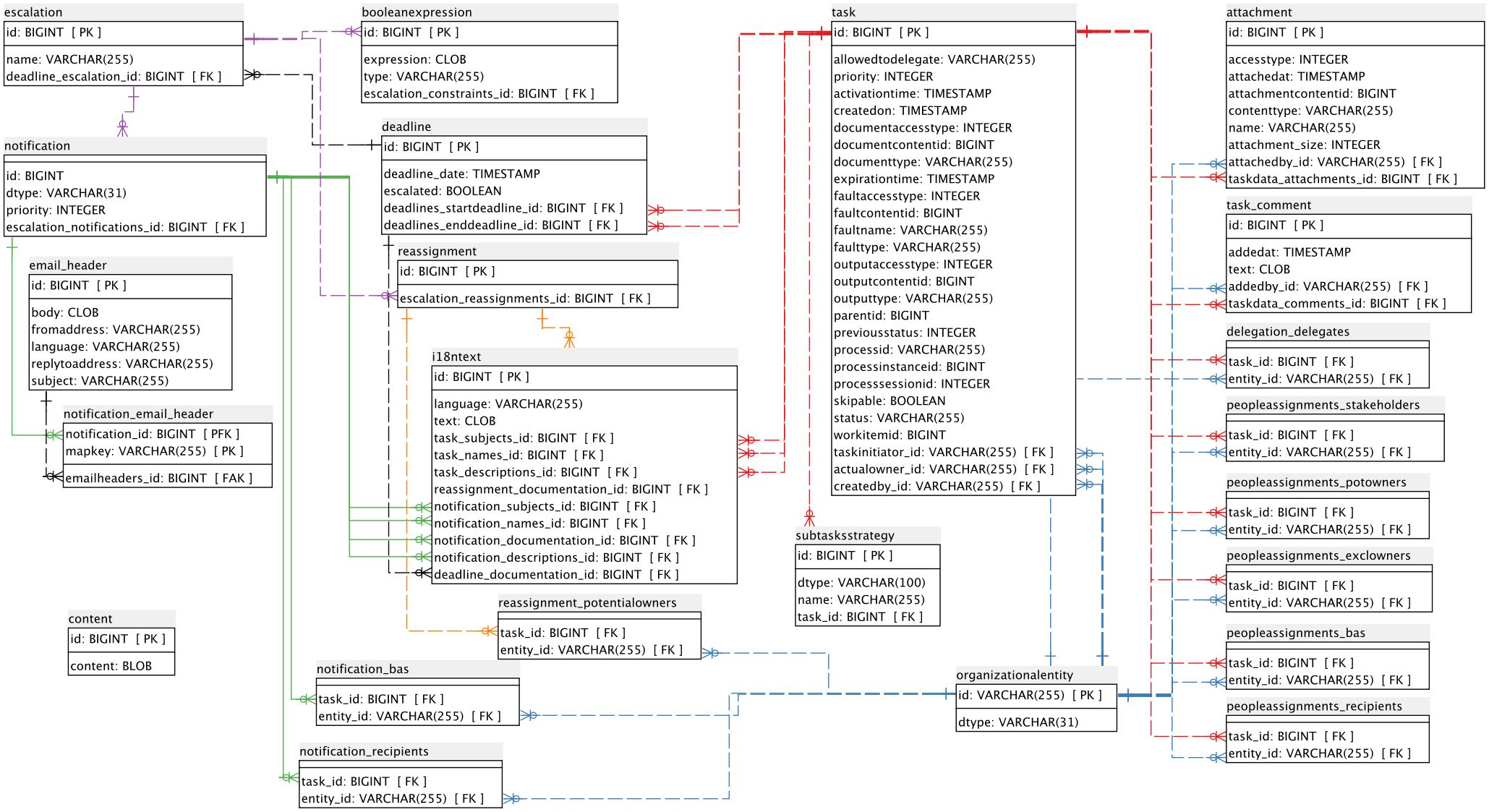
Figure 13.1. Human Task service data model
The data model above is organized around 2 groups of entities:
- The
taskentity which represents the main information for a task. (See the righthand side of the ERD above.) - The
deadline,escalationandnotificationentities which represent deadlines and escalations for a task as well as any notifications associated with those deadlines. (See the lefthand side of the ERD above.)
Two other main entities in the data model are the i18ntext and
organizationalentity.
- The
i18ntextentity is used to store text which may be language related, such as names or descriptions entered by users. - The
organizationalentityentity represents a user in some way.
The following paragraphs and tables describe the group of entities including
and associated with the task entity. These entities are shown on the right
hand side of the ERD. (See below for information about the deadline,
escalation and notification group of entities).
The column “FK” in the tables below, indicates whether or not a column in a database table has a foreign key constraint on it. If the “Nullable” column is empty, then the described database table column is nullable.
While a number of foreign key columns of different tables are specified as
non-nullable, many of these columns will simply contain the value -1 or
0 if there is no associated entity.
The task entity contains much of the essential information for
describing a task. Although a number of columns are not nullable, many of them
are simply set to "-1" if the value used in the column hasn't been set by
the task service.
Table 13.2. Task
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key of the task identity | NOT | |
priority | The priority of the task | NOT | |
allowedtodelegate | The group to whom this task may be delegated | ||
status | The status of the task | ||
previousstatus | The previous status of the task | ||
actualowner_id | The id of the organizational entity who owns the task | NOT | FK |
createdby_id | The id of the organizational entity who created the task | NOT | FK |
createdon | The timestamp describing when this task was created | ||
activationtime | The timestamp describing when this task was activated | ||
expirationtime | The timestamp describing when this task will expire | ||
skipable | Whether or not this task may be skipped | NOT | |
workitemid | The id of the work item associated with this task (see jBPM core schema) | NOT | |
processinstanceid | The id of the process instance associated with this task (see jBPM core schema) | NOT | |
documentaccesstype | How a document associated with the task can be accessed | ||
documenttype | The type of data in the document | ||
documentcontentid | The id of the content entity containing the document data | NOT | |
outputaccesstype | How the output document associated with the task can be accessed | ||
outputtype | The type of data in the output document | ||
outputcontentid | The id of the content entity containing the output document data | NOT | |
faultname | The name of the fault generated, if a fault occurs | ||
faultaccesstype | How the document associated with the fault can be accessed | ||
faulttype | The type of data in the fault document | ||
faultcontentid | The id of the content entity containing the fault document data | NOT | |
parentid | This is the id of the parent task | NOT | |
processid | The name (id) of the associated process | ||
processsessionid | The id of the associated (knowledge) session | NOT | |
taskinitiator_id | The id of the organizational entity who created the task | NOT | FK |
The subtasksstrategy entity is used to save the strategy that
describes how parent and sub-tasks should react when either parent or sub-tasks
are ended.
Table 13.3. SubTasksStrategy
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
dtype | A discriminator column | NOT | |
name | The name of the strategy | ||
task_id | The primary key of the associated task | NOT | FK |
The organizationalentity entity is extended to represent the different
people assignments that are part of the task.
Table 13.4. OrganizationalEntity
| Field | Description | Nullable |
|---|---|---|
id | The primary key | NOT |
dtype | The discriminator column | NOT |
The attachment entity describes attachments that have
been added to the task.
Table 13.5. Attachment
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
name | The (file) name of the attachment | ||
accesstype | How the attachment can be accessed | ||
attachedat | When the attachment was attached to the task | ||
attachment_size | The size (in bytes) of the attachment | ||
attachmentcontentid | The id of the content entity storing the raw data of the attachment | NOT | |
contenttype | The MIME type of the attachment data | ||
attachedby_id | The id of the organizationalentity entity that attached the attachment | NOT | FK |
taskdata_attachments_id | The id of the task entity to which this attachment belongs | NOT | FK |
The task_comment entity describes comments added to tasks.
Table 13.6. task_comment
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
addedat | The timestamp of when the comment was added to the task | ||
text | The text of the comment | ||
addedby_id | The primary key of the associated organizationalentity entity | NOT | FK |
taskdata_comments_id | The primary key of the associated task entity | NOT | FK |
The delegation_delegates table is a join table for relationships between
the task entity and the organizationalentity.
Table 13.7. delegation_delegates
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task | NOT | FK |
entity_id | The primary key of the associated organizationalentity | NOT | FK |
The peopleassignments_stakeholders table is a join table that describes
which organizationalentity entities are task stakeholders
of a particular task.
Table 13.8. peopleassignments_stakeholders
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The peopleassignments_potowners table is a join table that describes
which organizationalentity entities are potential
owners of a particular task.
Table 13.9. peopleassignments_potowners
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The peopleassignments_exclowners table is a join table that describes
which organizationalentity entities are the excluded
owners of a particular task.
Table 13.10. peopleassignments_exclowners
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The peopleassignments_bas table is a join table that describes which
organizationalentity entities are business administrators
of a particular task.
Table 13.11. peopleassignments_bas
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The peopleassignments_recipients table is a join table that describes
which organizationalentity entities are notification
recipients for a particular task.
Table 13.12. peopleassignments_recipients
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated task entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The following paragraphs and tables describe the group of entities having to do with deadline, escalation, and notification information. These entities are shown on the left hand side of the ERD diagram above.
The deadline entity represents a deadline for a task.
Table 13.13. deadline
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
deadline_date | The deadline date | ||
escalated | Whether or not the deadline has been escalated | NOT | |
deadlines_startdeadline_id | The id of the associated task entity which uses this deadline
as its start deadline. | NOT | FK |
deadlines_enddeadline_id | The id of the associated task entity which uses this deadline
as its end deadline. | NOT | FK |
The escalation entity descibes an escalation action that should be
taken for a particular deadline.
Table 13.14. escalation
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
name | The name of the escalation event | ||
deadline_escalation_id | The id of the associated deadline entity | NOT | FK |
The booleanexpression entity represents an expression that evaluates
to a boolean. These expressions are used in order to determine whether or not a
constraint should be applied.
Table 13.15. booleanexpression
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
expression | The expression text | ||
type | The type of expression | ||
escalation_constraints_id | The id of the escalation entity
for which this expression is used as a constraint | NOT | FK |
The notification entity describes a notification generated by an
escalation action.
Table 13.16. notification
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
dtype | The discriminator column | NOT | |
priority | The priority of the notification | NOT | |
escalation_notifications_id | The id of the associated escalation entity | NOT | FK |
The email_header entity describes an
e-mail that will be sent as part of a notification.
Table 13.17. email_header
| Field | Description | Nullable | |
|---|---|---|---|
id | The primary key | NOT | |
fromaddress | The e-mail address from which the e-mail is sent | ||
replytoaddress | The reply-to address used in the e-mail | ||
language | The language in which the e-mail is written | ||
subject | The subject of the e-mail | ||
body | The body of the e-mail |
The notification_email_header table is a join table that
describes and qualifies which email_header entities are part of a
notification.
Table 13.18. notification_email_header
| Field | Description | Nullable | FK |
|---|---|---|---|
notification_id | Together with the mapkey, this field is part of the
primary key. This field refers to the notification entity that
the email_header is associated with. | NOT | FK |
mapkey | Together with the mapkey, this field is part of the
primary key. This field describes what the type is of the associated
email_header. | NOT | |
emailheaders_id | The id of the associated email_header entity | NOT | FK |
The reassignment entity describes reassignments associated with
escalations.
Table 13.19. reassignment
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
escalation_reassignments_id | The id of the associated escalation entity | NOT | FK |
The reassignments_potentialowners table is a join table that describes
which organizationalentity entities are potential
owners if a reassignment happens as part of an escalation.
Table 13.20. reassignment_potentialowners
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated reassignment entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The notification_bas table is a join table that describes which
business administrators will be notified by a
notification.
Table 13.21. notification_bas
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated notification entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The notification_recipients table is a join table that describes which
recipients entities will be received a notification.
Table 13.22. notification_recipients
| Field | Description | Nullable | FK |
|---|---|---|---|
task_id | The primary key of the associated notification entity | NOT | FK |
entity_id | The primary key of the associated organizationalentity entity | NOT | FK |
The content entity represents the content of a document, output
document, fault or other object.
The i18ntext entity is used by a number of different other entities
to store text fields. The deadline, notification,
reassignment and task entities use this entity to store
descriptions, subjects, names and other documentation.
Although all foreign keys are not nullable, they will be set to 0 if they are not being used.
Table 13.24. i18ntext
| Field | Description | Nullable | FK |
|---|---|---|---|
id | The primary key | NOT | |
language | The language that the text is in. | ||
text | The text | ||
task_subjects_id | The id of the task entity for which this is a subject | NOT | FK |
task_names_id | The id of the task entity for which this is a name | NOT | FK |
task_descriptions_id | The id of the task entity for which this is a description | NOT | FK |
reassignment_documentation_id | The id of the reassignment entity for which this is documentation | NOT | FK |
notification_subjects_id | The id of the notification entity for which this is a subject | NOT | FK |
notification_names_id | The id of the notification entity for which this is a name | NOT | FK |
notification_documentation_id | The id of the notification entity for which this is documentation | NOT | FK |
notification_descriptions_id | The id of the notification entity for which this is a description | NOT | FK |
deadline_documentation_id | The id of the deadline entity for which this is documentation | NOT | FK |